You probably know already the concept of the Pi-hole. If not: It’s a (forwarding) DNS server that you can install on your private network at home. All your clients, incl. every single smartphone, tablet, laptop, and IoT devices such as smart TVs or light bulb bridges, can use this Pi-hole service as their DNS server. Now here’s the point: it not only caches DNS entries, but blocks certain queries for hostnames that are used for ads, tracking, or even malware. That is: You don’t have to use an ad- or track-blocker on your devices (which is not feasible on smart TVs or smartphone apps, etc.), but you’re blocking this kind of sites entirely. Nice approach!
Yes, there are already some setup tutorials for the Pi-hole out there. However, it’s not only about installing the mere Pi-hole, but setting it up with your own recursive DNS server (since the default installation forwards to public DNS servers), using DNSSEC, and adding some more adlists. That’s why I am listing my installation procedure here as well. However, it’s not a complete beginners guide. You’ll need some basic Linux know-how.
I am using a Raspberry Pi 3 B+ Rev 1.3 with Raspberry Pi OS for this setup. (While in the meantime I’m running Pi-hole on my Intel NUC with Ubuntu server.)
Well, that was easy. It will ask you some questions though. Note the lines at the end about your admin password and how to access the console:
[i] Web Interface password: Q_1kJLS9
[i] This can be changed using 'pihole -a -p'
[i] View the web interface at http://pi.hole/admin or http://192.168.7.53/admin
Own Recursive DNS Server & DNSSEC
By default, Pi-hole uses some public DNS servers for its name resolution. I don’t like that concept because you’re giving 100 % of your queries to some third parties. I prefer using my own recursive DNS server. (Yes, I know that your upstream ISP is still able to see your queries, but that’s by far better than using 8.8.8.8 or the like.) The recursive DNS server of choice is Unbound. The following installation procedure is covered on the Pi-hole site as well.
sudo apt update
sudo apt install unbound
While this installation is working, the Unbound service is not able to start yet because the UDP/TCP port 53 is already used by Pi-hole. You have to use an adapted config anyway:
server:
# If no logfile is specified, syslog is used
# logfile: "/var/log/unbound/unbound.log"
verbosity: 0
interface: 127.0.0.1
port: 5335
do-ip4: yes
do-udp: yes
do-tcp: yes
do-ip6: yes
# You want to leave this to no unless you have *native* IPv6. With 6to4 and
# Terredo tunnels your web browser should favor IPv4 for the same reasons
prefer-ip6: yes
# Use this only when you downloaded the list of primary root servers!
# If you use the default dns-root-data package, unbound will find it automatically
#root-hints: "/var/lib/unbound/root.hints"
# Trust glue only if it is within the server's authority
harden-glue: yes
# Require DNSSEC data for trust-anchored zones, if such data is absent, the zone becomes BOGUS
harden-dnssec-stripped: yes
# Don't use Capitalization randomization as it known to cause DNSSEC issues sometimes
# see https://discourse.pi-hole.net/t/unbound-stubby-or-dnscrypt-proxy/9378 for further details
use-caps-for-id: no
# Reduce EDNS reassembly buffer size.
# Suggested by the unbound man page to reduce fragmentation reassembly problems
edns-buffer-size: 1472
# Perform prefetching of close to expired message cache entries
# This only applies to domains that have been frequently queried
prefetch: yes
# One thread should be sufficient, can be increased on beefy machines. In reality for most users running on small networks or on a single machine, it should be unnecessar>
num-threads: 1
# Ensure kernel buffer is large enough to not lose messages in traffic spikes
so-rcvbuf: 1m
# Ensure privacy of local IP ranges
private-address: 192.168.0.0/16
private-address: 169.254.0.0/16
private-address: 172.16.0.0/12
private-address: 10.0.0.0/8
private-address: fd00::/8
private-address: fe80::/10
Restart and verify the running service:
sudo systemctl restart unbound
sudo systemctl status unbound
Since the DNS from Unbound is now running on port 5335, use this command to test it:
dig pi-hole.net @127.0.0.1 -p 5335
And since DNSSEC validation is turned on, you should see the “ad” flag for a DNSSEC signed FQDNs, while a “SERVFAIL” for DNSSEC errors:
Use this DNS service within Pi-hole by enabling it in this way:
Including More Lists Automatically
Right now you are using one single ad-list on your Pi-hole. While that’s a good starting point, you definitely want to add some more lists. Note that once a list is added, Pi-hole will automatically update the list entries. What we are doing right now is to automatically add more lists in general. Two steps are required for this: 1) A script that checks a “list of lists” in order to add them into the Pi-hole. I am using this: pihole-updatelists:
Enabling and starting pihole-updatelists.timer...
Created symlink /etc/systemd/system/timers.target.wants/pihole-updatelists.timer /etc/systemd/system/pihole-updatelists.timer.
That is: it installs a timer that runs once a week in order to update the lists.
2) Adding a “list of lists”. You first have to choose such a list. Keep in mind that you must trust the source of this list! I have chosen “The Firebog” project which lists some lists out of the following categories: suspicious, advertising, tracking & telemetry, malicious. With the following list, all the lists that are checked (ticked) from their site are listed: https://v.firebog.net/hosts/lists.php?type=tick. Haha, how many times have I said “lists”? ;)
Add this “list of lists” to the pihole-updatelists configuration like this:
That’s it. You can either wait till next Saturday to have it updated, or you do it manually for this first time (of course!) with the following command:
pihole-updatelists
After that you’ll see some more configured adlists at Group Management -> Adlists:
While the “Domains on Blocklist” counter at the upper right should increase significantly as well. In my case, it’s greater than 250.000 entries. Nice!
Miscellaneous
By the way: Don’t forget to change your DHCP settings on your router to use the Pi-hole as the DNS server. ;) Here’s what it looks like on an AVM Fritzbox (IPv4 and IPv6) and on a Ubiquiti UniFi network:
Here’s a little pitfall I ran into at least two times: If your Pi has no valid time (e.g. when it was offline for a couple of days), while you’re using DNSSEC (as I do!), you’ll have a chicken-and-egg problem. The NTP service won’t be able to lookup its NTP server addresses because of DNSSEC failures (due to the wrong time), while DNSSEC will never be able to validate DNS responses unless NTP corrects the local time. Arg! The only way to solve this is to manually correct the time on the pi with:
sudo date-s'2021-01-04 13:04:00', click for details. If you’re interested in the DNSSEC validation process on the Pi-hole, read this: “Understanding DNSSEC validation using Pi-hole’s Query Log“.
Final tip: I recommend the free Pi-hole Remote App for iOS. It works like a charm and is completely ad-free. Wow. You can donate through in-app purchases, though, which I recommend as well. Here as some screenshots:
I’m ending this story with a screenshot from my Pi-hole dashboard. I really like it:
I wish you a blessed Christmas. Jesus is born <- that’s what Christmas is all about!
Neben dem Gebastel mit technischen Geräten macht mir vor allem das Spielen von Saiteninstrumenten viel Spaß. So haben sich mit der Zeit ein paar Insturmente aller Couleur angesammelt: E-Gitarren, Akustik-Gitarren, Bässe, Ukulelen. Gleichermaßen begeistern mich schon seit Jahren die tollen Metall-Kreisel von ForeverSpin, einem kanadischen Unternehmen, welches aus massiven Blöcken per CNC-Drehmaschine sehr akurate Kreisel herstellt. Neben bekannten Metallen wie Stahl, Aluminium oder Messing kommen auch Exoten wie Magnesium, Zirconium, Titan oder Wolfram (!) zum Einsatz.
Nun, die Verbindung dieser beiden Interessen besteht wie folgt: In den letzten Jahre habe ich diese Kreisel (englisch: top) auf verschiedenen Gitarren Oberflächen (englisch ebenfalls: top) fotografiert. Die entstandenen Bilder sind allesamt auf Unsplash zu sehen. In diesem Blogpost geht es nun um die individuellen Zusammenstellungen der Kreisel zu den Gitarren und was sich der Künstler dabei gedacht hat. ;) Es bringt dem Otto Normalverbraucher also eigentlich nichts, hier weiterzulesen. Eher macht es vor allem mir einfach Spaß.
Über 20 verschiedene ForeverSpin Kreisel gibt es – und es wird immer mal einer mehr. Zusätzlich eine Reihe von eingefärbten Aluminium-Kreiseln, welche man zu gesonderten Marketing-Aktionen dazugeschenkt bekommen hat. Beim Fotografieren hatte ich immer folgendes Prinzip: Die echten Metall-Kreisel kommen auf die Gitarren, die gefärbten Kreisel auf Effektgeräte.
Fotos
Hier erst mal eine Galerie des jeweils besten Fotos jeder Session:
Auf Unsplash findet ihr in dieser Collection genau die gleichen Fotos. Da auch zum kostenlosen Download zum Weiterverwenden.
Geholfen haben mir sowohl beim Fotografieren also auch beim Bearbeiten unter anderem Nicolai S., Jörg-Michael W., Evelyn W. und Simon d. V.. Meinen herzlichsten Dank euch an dieser Stelle! Mittlerweile (Stand 2021) habe ich mich neben dem Schießen auch selbst an Lightroom rangetraut und bin quasi eigenständig.
Welcher Kreisel auf welcher Gitarre?
Das war für mich die zentrale Frage. Da ich mir durchaus bei allen Beziehungen etwas gedacht habe, schreibe ich das hier mal runter. Die Auflistung spiegelt die Reihenfolge der Fotosessions wider und ist somit analog zum Veröffentlichungsdatum der Bilder.
Stainless Steel Mirror (Rostfreier Stahl Spiegeloberfläche) – Epiphone Les Paul Standard Plustop Pro Translucent Blue(E-Gitarre): Es war mein erster Kreisel welcher durch seine sehr gläzende Oberfläche heraussticht. (Viele andere Kreisel sind entweder nicht so “sauber” von der Oberfläche wie z.B. der in roségold, oder sie bekommen eine Patina wie z.B. Magnesium oder Kupfer.) Dieser Glanz hat mich an die Humbucker Pickups meiner Paula erinnert, daher die Wahl.
Magnesium – Ortega RFU10ZE(Sopran-Ukulele aus Zebraholz): Einfache Sache: Mit 6 Gramm ist der Magnesium Kreisel der leichteste aller verfügbaren ForeverSpin Tops und kam daher auch auf die kleinste (und ebenfalls leichteste) Gitarre im Hause Weber. Die Ukulele war damals ein Werbegeschänk von der Zeitschrift Gitarre & Bass, da ich einen Bekannten für ein Abo geworben hatte. Coole Sache. Anmerkung: Die ersten Fotos hatten wir gemacht ohne vorher die Korrosion von dem Magnesium entfernt zu haben. Daher wirkt der Kreisel relativ dumpf. Frisch poliert sieht er ganz anders aus.
Damascus Steel (Damastzener Stahl / Damast) – Warwick RB Corvette $$ 5 Honey Violin Transparent Satin (E-Bass): Von der Oberfläche schön vergleichbar die beiden, hat sowohl der Damast Kreisel als auch die Maserung des Holzbasses eine gut erkennbare Ähnlichkeit. Beide fühlen sich einfach toll an.
Green Mystery – Ibanez Tube Screamer TS9 (E-Gitarren Effektgerät): Wie gesagt: kein reiner Metall-Kreisel und daher nichts für den Puristen der reinen Metallsorten. Deswegen bekommt er auch kein Instrument, wohl aber ein farblich ähnliches und ebenfalls unerlässliches Produkt aus den Requisiten eines E-Gitarrenspielers: Den Tube Screamer, also DEN Verzerrer schlecht hin.
Rose Gold Plated (Rosévergoldet) – Fender Standard Jazz Bass MN AW (E-Bass): Das Mädchen unter den Kreiseln habe ich nur gekauft, weil meine Frau ihn toll fand. ;) Klischee bestätigt. Dieser schöne Kreisel bedarf eines ebenso schönen Instruments, welches durch den komplett weiß lackierten Jazz Bass erfüllt wird. (Anmerkung: Dieses Instrument gehört nicht mir, sondern meinem Bruder.)
Pink Mystery – Mad Professor Snow White AutoWah (E-Gitarren Effektgerät): Weil sie farblich so gut passen. Nicht. ;) Oder zumindest halb, weil zu weiß ja fast alles passt. Wieder einer der lackierten und somit nicht “originalen” Metall-Kreisel. Den Auto Wah-Wah mag ich vom Effekt her sehr, vor allem für schnelle funkige Sounds.
Black Zirconium – Epiphone Viola Bass (E-Bass): Weil es der schönste Frauenname der Welt ist (und nebenbei auch für das Musikinstrument Bratsche steht). Ein eleganter, seriöser Bass, welchen ich mir zusätzlich zum Frestless hab umbauen lassen, siehe hier. Dies erforderte ebenfalls einen anständigen Kreisel, hier in Form eines schwarzen Anzugs.
Stainless Steel (Rostfreier Stahl) – Squier by Fender Affinity Series Stratocaster (E-Gitarre): Meine allererste E-Gitarre. Aus heutiger Sicht nichts besonderes, aber dennoch ein solides Anfängerinstrument. Gleiches gilt für den stinknormalen Stahl – nichts besonderes, aber solide. Passt also zusammen. Etwas härter durfte ich bei den Fotos hier schon rangehen. So waren es -2 °C auf der geschotterten Fläche im Bereich eines Straßenbaus. Teilweise sieht man, dass die Strat angefangen hat zu frieren. Sie hat’s überlebt. Schwieriger war der Einsatz des grünen Laserpointers: Auf Grund der Kälte sind die älteren Batterien so in der Spannung abgesunken, dass er teilweise gar nicht mehr geleuchtet hat.
Aluminium – Career Bass (E-Bass, keine Infos im Web): Bitte was für ein Bass? Career? Ja, genau, sagt mir auch nichts. Das war mein erster Bass den ich im zarten Alter von 13 zu Weihnachten bekommen habe und der mir viele viele Jahre als einziger Bass in meinem Leben zur Seite gestanden ist. Online findet man über ihn quasi nix. Gefallen tut mir das in den Korpus eingearbeitete Logo. Da er einen verkleinerten und leichten Korpus hat, passt der ebenfalls leichte Aluminium Kreisel ganz gut zu diesem Gerät. Seit ich mein Arsenal an Bässen etwas aufgestockt habe, spiele ich diesen Klassiker quasi gar nicht mehr. Deswegen hing er erst einige Jahre in unserer damaligen Gemeinde zur allgemeinen Verwendung rum, bevor ich ihn Ende 2018 an einen Jugendlichen verschenkt habe.
24Kt Gold Mirror (24 Karat Spiegeloberfläche) – Ovation Preacher Deluxe (E-Gitarre, keine offiziellen Online-Resourcen vorhanden): Modell Nummer 1283-5 aus dem Jahre 1975 in schwarz. Haha, ja es gab für kurze Zeit mal ein paar E-Gitarren von Ovation. Solidbody, made in USA. Habe das edle Teil von einem älteren Mann bei uns im Haus geerbt. Es ist meine mit Abstand älteste und auch wertvollste Gitarre – nicht nur materiell, sondern auch ideell! Farblich passt der polierte Goldkreisel super dazu. Die Fotos sind übrigens auf dem Parkplatz vor der Fischauktionshalle in Hamburg entstanden.
Black Mystery – Seymour Duncan SFX-07 Shape Shifter (E-Gitarren Effektgerät): Toller Tremolo Effekt, welcher die Geschwindigkeit des LFOs auch per Tap und verschiedenen Ratios einstellen kann. Mittlerweile gibt es genau dieses Effektgerät nicht mehr – es wurde durch eine neuere Variante in Stereo abgelöst. Egal, mir reicht er in Mono. Der schwarze Kreisel passt farblich einfach gut.
During the last weeks, I had an interesting request to publish NTP servers to client systems by using DHCPv6 in an IPv6 only network. Our Fortigate (or me?) had to learn how to publish the information. Hence this post is not only about NTP and IPv6, but a small guide on how to walk through RFCs and how to get out the relevant information. I’m very happy I got the possibility to share my experience here. Thank you, Johannes!
It started with a small question from my co-worker: “Can you send our NTP servers with DHCP in the IPv6 only network?” And my first idea was: “I’m sure, I can configure this within of minutes.” But 10 minutes later I had to change my mind: it takes me more time to understand how I have to configure this. The simple reason for this is the missing option in the system configuration, the vendor didn’t implement (yet)…
I will show how to manage this with a FortiGate (FortiOS 6.0.14, there is no newer version available for this model) operating as a DHCPv6 server. At the time of beginning, the DHCP6 server configuration looks like this:
config system dhcp6 server
edit 641
set rapid-commit enable
set lease-time 3602
set domain "example.com"IP
set subnet 2001:db8:c:641::/64
set interface "IPv6only-01"
config ip-range
edit 1
set start-ip 2001:db8:c:641::6401
set end-ip 2001:db8:c:641::64ff
next
end
set dns-server1 2001:db8:c:a53::53
set dns-server2 2001:db8:c:b53::53
next
end
As you can see, the DHCPv6 server is configured to publish a domain name and two DNS servers for recursive name resolution. Further on there’s an IPv6 range for stateful DHCPv6. But FortiOS didn’t allow me to configure the NTP server directly. But it allows me to send three self-defined options in DHCPv6:
config system dhcp6 server
edit < id >
set option1 {string} Option 1.
set option2 {string} Option 2.
set option3 {string} Option 3.
next
end
Could this be the way to fulfil my co-worker’s request? And how to create the {string} to send an IPv6 address or hostname to the client system? Having a look at the CLI of the FortiGate:
config system dhcp6 server
edit < id >
(server) # set option1 ?
< option-code > [< options >] options must be even number of hexadecimal characters(optional)
This information didn’t help me. Now it looks like nothing else than reading RFCs helps. :-(
Digging through RFCs
In the list of FortiOS 6.0 supported RFCs, RFC 3315 is mentioned. But in RFC 3315 is no useful information about NTP… Reading the new RFC for DHCPv6, RFC 8415, you can find in section 24 a list of DHCPv6 options and the link to the complete list of DHCPv6 parameters assigned by IANA. Looks like that’s the information I need.
There is an option with the name “NTP Server”, number 56 (decimal), but the information about the order and possible values are somewhere else: in RFC 5908.
In RFC typical style there (RFC 5908 on page 4) you can find the required format of the option to send NTP-server information to the client system:
The format of the NTP Server Option is:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| OPTION_NTP_SERVER | option-len |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| suboption-1 |
: :
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| suboption-2 |
: :
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
: :
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| suboption-n |
: :
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
option-code: OPTION_NTP_SERVER (56),
option-len: Total length of the included suboptions.
For the ones who never had the need to read something like this, a few hints which helped me:
The headline of the “table” are the bits, starting from 00 to 31 = 32bit.
The field OPTION_NTP_SERVER is a 16-bit value and the field option-len is a 16bit value, too.
The next fields suboption-1, suboption-2 to suboption-n has, at this point, no fixed length; but at least 32bit. This is because there is a pipe character on the left and right side, that indicates: this line is required. The next line, which has a colon at both sides, tells us it has a variable length, 0 or more lines.
To find the next piece of the puzzle, we continue reading the next page in RFC 5908 (page 5). Here we find how to format the sub-options:
The format of the NTP Server Address Suboption is:
The field NTP_SUBOPTION_SRV_ADDR is a 16-bit value and the field suboption-len is a 16bit value, too.
The next field (IPv6 address of NTP server) has a fixed length of 128 bit (4 lines with 32 bit). I hope you already expected this length. :-)
OK, we try to understand the information we have until now: We have to set the option number for the NTP server, which is 56 (dec) and 0x38 (hex). The NTP_SUBOPTION_SRV_ADDR has a sub-option code of 1 (0x0001 as 16bit hex value) and a suboption-length of 16 octets (if it is easier for you: 16 bytes). Then we have to put in the IPv6 (unicast-) address of the server. We take 2001:0db8:2800:0000:0000:0000:0ac3:0123 as an example. In the end, we calculate the complete length of the option and put the value in the field option-len:
2 octets for the NTP suboption field
2 octets for the NTP suboption length
16 octets for the NTP IPv6 server address
In summary 20 octets (0x14 in hex) is the calculated value for the field option-len. If we put in all the data, the fields look like this:
But in FortiOS this is different than expected (by me?): we don’t have to calculate and put in the option-length here! We just need the option code (in decimal = 56) and the option value in hexadecimal characters as in the following line:
(server) # set option1 56 '0001001020010db828000000000000000ac30123'
NTP_SUBOPTION_SRV_ADDR | |
suboption-lenght | IPv6 unicast address of NTP server
It took me a few hours with Wireshark to realize this…
Publishing FQDNs
My co-worker was quite happy about my phone call with the good news. But: is publishing an IPv6 unicast address a good solution for the future? I decided no, I want to publish an FQDN.
Now, as I did understand the format of the NTP-server option, I had a look for how to publish the name of the NTP server. For this we have to read section 4.3 on page 6 of RFC 5908. The format of the NTP Server FQDN Suboption is:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| NTP_SUBOPTION_SRV_FQDN | suboption-len |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| |
| FQDN of NTP server |
: :
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
suboption-code: NTP_SUBOPTION_SRV_FQDN (3),
suboption-len: Length of the included FQDN field,
FQDN: Fully-Qualified Domain Name of the NTP server or SNTP server.
This field MUST be encoded as described in [RFC3315],
Section 8. Internationalized domain names are not allowed
in this field.
Let’s have a try to send the hostname 3.de.pool.ntp.org to the client systems.
The FQDN must be encoded as described in section 8 of RFC 3315. The few lines there tell us to read section 3.1 of RFC 1035 but MUST NOT use the compressed form as described in section 4.1.4 of RFC 1035. And we MUST NOT use an IDN (internationalized domain name)!
This is how encode the hostname 3.de.pool.ntp.org based on section 3.1 in RFC 1035: First of all, we have to specify the length of the next part of the hostname (also called: label):
one character which results in value 1 (0x01) followed by the ascii-code of the character 3: 0x33.
Repeat this for the next label: length of 0x02 followed by 0x6465 for de
For the next label: length (4 octets) and the word pool results in data 0x04706f6f6c
And so on: length (3 octets) and data are 0x036e7470 for ntp
One time similar again: length (3 octets) and data are 0x036f7267 for org
And now, very important: notification for end of hostname: 0x00
I repeat the whole hexadecimal characters (separated with space characters for a better understanding):
01 33 02 6465 04 706f6f6c 03 6e7470 03 6f7267 00
3 . d e . p o o l . n t p . o r g
This is the FQDN for the NTP suboption. Now we have to calculate the length of the suboption: 19 octets, 0x13 in hex.
My line for configuring the hostname 3.de.pool.ntp.org in FortiOS looks is this one:
(server) # set option2 56 '00030013013302646504706f6f6c036e7470036f726700'
suboption type = FQDN | |
suboption length = 19dec = 0x0013 | FQDN as described a few lines above
Do you want to publish two FQDNs? For example 2.de.pool.ntp.org and 3.de.pool.ntp.org? No problem, just do it:
(server) # set option2 56 '00030026013202646504706f6f6c036e7470036f726700013302646504706f6f6c036e7470036f726700'
But this wasn’t a good solution for my co-worker. He was not able to configure his client with the information I sent by DHCPv6. (Please don’t ask me for details!) Next, he asked me to send the SNTP address.
What about SNTP?
A fast search and I found the next interesting RFC with the name Simple Network Time Protocol (SNTP) Configuration Option for DHCPv6: RFC 4075. Looking on page 2:
The format of the Simple Network Time Protocol servers option is as
shown below:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| OPTION_SNTP_SERVERS | option-len |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| |
| SNTP server (IPv6 address) |
| |
| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| |
| SNTP server (IPv6 address) |
| |
| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
: ... :
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
option-code: OPTION_SNTP_SERVERS (31)
option-len: Length of the 'SNTP server' fields, in octets;
it must be a multiple of 16
SNTP server: IPv6 address of SNTP server
SNTP is option code 31, FortiOS is calculating the option length itself, we just need the IPv6 unicast (only unicast?) address of the SNTP server
(server) # set option3 31 '20010db828000000000000000ac30123'
Do you want to publish two SNTP servers? No problem, do it like this:
(server) # set option3 31 '20010db828000000000000000ac2012320010db828000000000000000ac30123'
FortiOS and RouterOS Configuration
Today, the DHCP6 server configuration of the FortiGate looks like this:
config system dhcp6 server
edit 641
set rapid-commit enable
set lease-time 3602
set domain "example.com"
set subnet 2001:db8:c:641::/64
set interface "IPv6only-01"
set option1 56 '0001001020010db828000000000000000ac30123'
set option2 56 '00030013013302646504706f6f6c036e7470036f726700'
set option3 21 '20010db828000000000000000ac30123'
config ip-range
edit 1
set start-ip 2001:db8:c:641::6401
set end-ip 2001:db8:c:641::64ff
next
end
set dns-server1 2001:db8:c:a53::53
set dns-server2 2001:db8:c:b53::53
next
end
FortiOS in 6.0.14 allows only 3 custom values, I can’t publish more custom options. One more feature request to Fortinet: please allow more (maybe 9?) custom options here. :-)
In the same way, it’s possible to publish other information with DHCPv6, if the operating systems of the server allow the administrator to publish custom values in DHCPv6. In some operating systems, at the time of writing these lines, it’s the only way to send even basic information to a client system. For example, if you have to do a similar configuration in MikroTik RouterOS (tested with 6.48.5), it looks like this:
In my experience, RouterOS is sending only requested options, other than FortiOS. In RouterOS, we don’t have to calculate the length of the DHCPv6 option, too.
Please always keep in mind: if you don’t send at least the other-flag in RA packets, most client systems don’t try to get DHCPv6 information from the network.
Some months ago, my co-worker and I ran into an interesting issue: a notebook with a newly installed Ubuntu 20.04 does only work with IPv4, but this office network is dual-stacked (IPv4 and IPv6). Other Linux clients as well as Windows and Mac systems still work fine. They all get an IPv4 configuration by DHCPv4 and an IPv6 configuration by stateful DHCPv6 from the same DHCP server, relayed by a Cisco ASA 5500-X. What’s wrong with Ubuntu 20.04?
Our first idea was, that we forgot to activate global IPv6 during installation. But it was enabled. Our next idea was an active local firewall that blocks DHCPv6 packets or IPv6 in general. This is a frequent problem because DHCPv6 is using UDP ports 546 and 547. But the same notebook at a home network works fine with IPv6 and IPv4. We had to look at our network…
In this network, a Cisco ASA is acting as the default router to the internet. It’s also acting as a DHCP relay system for IPv4 and IPv6 to forward DHCP packets of the clients to the central DHCP server and back. But the DHCPv6 server didn’t get a SOLICIT message from the client; DHCPv4 works.
Some log lines from the ASA got our attention:
DHCPv6: Bogus option CLIENTID(1), len 18
IPv6 DHCP_RELAY: Discard SOLICIT with invalid or no options
At this time we didn’t understand the log lines. Because we had no better idea, we decided to activate some debug commands at our ASA:
Maybe that’s a few commands too much, but we wanted to get a hint of what we are doing wrong. Less than 100 seconds later we got the following lines:
8410825.8800: DHCPv6: Received SOLICIT from fe80::3afd:e025:f6b:75d9 on vlan6
8410825.8800: IPv6 DHCP: detailed packet contents
8410825.8800: src fe80::3afd:e025:f6b:75d9 (vlan6)
8410825.8800: dst ff02::1:2
8410825.8800: type SOLICIT(1), xid 4903931
8410825.8800: option RAPID-COMMIT(14), len 0
8410825.8800: option IA-NA(3), len 12
8410825.8800: IAID 0x2d1aa133, T1 0, T2 0
8410825.8800: option UNKNOWN(39), len 10
8410825.8800: option ORO(6), len 8
8410825.8800: DNS-SERVERS,DOMAIN-LIST,UNKNOWN,SNTP-ADDRESS
8410825.8800: option CLIENTID(1), len 18
8410825.8800: 0004xxxxxxxxxxxxxxxxxxxxxxxxxxxxFDA2
8410825.8800: option ELAPSED-TIME(8), len 2
8410825.8800:
8410825.8800: IPv6 DHCP_RELAY: DHCPD/RA: Message received from cluster module
8410825.8800: DHCPv6: Bogus option CLIENTID(1), len 18
8410825.8800: IPv6 DHCP_RELAY: Discard SOLICIT with invalid or no options
This tells us: there is a client that wants to get an IPv6 configuration (solicit) but the ASA decides the DHCPv6 client ID with a length of 18 octets is wrong. Because of this, the ASA throws away the solicit message.
OK. Now we know the device which causes the problem. But what’s wrong?
We searched around and found, Cisco knows this issue: ASA dropping DHCPv6 SOLICIT from Unix-based systems (unfortunately only accessible with a Cisco Account). They recommend a workaround: “Modify the client UUID to use UUID of 1”. We had no idea why changing the system UUID should be a way to get DHCPv6 working…
Now we had a more detailed look at the messages we got in the ASA console. There we saw from Windows system lines like this:
8411325.7600: option CLIENTID(1), len 14
8411325.7600: 0001000126C41D660050568FADC3
The Ubuntu system causes these lines:
8411955.8800: option CLIENTID(1), len 18
8411955.8800: 000416BD597F6092FBB0866BC7B6E23DFDA2
Some more hours later we understood the issue like this: Cisco implemented the relaying of DUID types 1-3, [not UUID!] defined in RFC3315 (July 2003), but not the additional DUID type 4, defined in RFC6355 (August 2011). And we get the hidden hint from Cisco for their workaround: change the DUID (DHCP unique identifier) to a type 1 DUID.
For Ubuntu Linux we didn’t find a (for us working) way the change DUID type to 1; but in a new Debian 10 installation of another co-worker, we run in a similar issue. After installation the system used a DUID type 4, too:
For the Debian Linux system, we found the workaround: we delete the lease file and create a new one with a DUID type 1 (DUID-LLT = link-layer address plus time ).
Of course, you can use a DUID type 2 (vendor-assigned unique ID based on Enterprise Number) or DUID type 3 (link-layer address), too.
This is just a workaround for a network with less affected clients. If you have to publish this solution for a large bring-your-own-device (BYOD) network with many affected clients: Have fun!
If someone has a hint on which file we need to change or delete at Ubuntu Linux, please write a few lines about it in the comments. Thanks!
At the time of writing these lines, there is an update at the Cisco case which indicates that there should be a new version of the ASA operating system which should fix the DUID type 4 issue of the DHCPv6 relay agent. We are looking forward to get the new version, maybe in a few years. :-)
This post is about adding an own (trusted) X.509 certificate for the HTTPS GUI of the Cisco Application Policy Infrastructure Controller aka APIC. You can do this via the GUI itself or via the API. Here are both ways:
A few preliminary comments: Yes, it is not a MUST to have a valid certificate on your APIC in order to access it. But it is definitely a best practice to do so! You can either use your own PKI within your enterprise or you’re using a public trusted CA for this. For this guide, I’m using our own PKI. The process of generating the server certificate and signing it by the intermediate certificate is not part of this post though. In any case, you need the intermediate & root certificate as well as the server certificate and its private key. Everything should be in the PEM format, that is: base64 encoded DES format, with an unencrypted private key. I am using APIC Version 5.2(2f) for the post.
Via GUI
Adding a trusted certificate involves the following steps: 1) Adding the root AND intermediate certificate, 2) importing the actual server certificate incl. its private key, and 3) activating this server certificate. (Refer to Cisco APIC Security Configuration Guide, Chapter: HTTPS Access.)
You have to concatenate the intermediate + root certificate (in that order!) to upload it as a certificate authority. Navigate to: Admin -> AAA -> Security -> Public Key Management -> Certificate Authorities -> Create Certificate Authority. Give it a speaking name and paste the mentioned certificate chain into it.
To add the server certificate, go to “Key Rings” and “Create Key Ring”. Give it a name, select the certificate authority you just added, and paste the certificate as well as the private key.
To activate the certificate, navigate to Fabric -> Fabric Policies -> Policies -> Pod -> Management Access -> default and select the just added “Admin KeyRing”.
Via API
In case you are automating everything or at least a bit, you can use the API to get those certs into the APIC. It’s always a POST into the following URL, as seen by Postman in my samples:
The adding involves the same three steps as mentioned before:
10 Install Intermediate +Root CA:
<?xml version="1.0" encoding="UTF-8"?>
<imdata totalCount="1">
<pkiTP annotation="" certChain="-----BEGIN CERTIFICATE-----
[this is the intermediate cert]
-----END CERTIFICATE-----
-----BEGIN CERTIFICATE-----
[this is the root cert]
-----END CERTIFICATE-----" descr="" dn="uni/userext/pkiext/tp-Own-PKI-Inter-and-Root" name="Own-PKI-Inter-and-Root" nameAlias="" ownerKey="" ownerTag=""/>
</imdata>
20 Install Device Cert + Private Key. Note the reference to the trust point (intermediate + root CA) with the tp=”…” parameter:
Ich durfte zu Gast bei der #heiseshow zum Thema IPv6 sein. In Anlehnung an die Artikelserie über IPv6 in der c’t 7/2022, in der auch mein Artikel über die Vorteile von IPv6-Adressen erschienen ist, ging es bei diesem Video-Podcast um gängige Fragen zu IPv6 sowohl im Heimanwender- als auch im Enterprise-Segment. Ne knappe Stunde lief die Schose und ich empfand es als ziemlich kurzweilig. ;)
Lange Rede, wenig Sinn – hier ist der Podcast:
Natürlich war es keine didaktisch ausgearbeitete Grundlagenschulung für IPv6, sondern mehr ein fröhliches Durcheinander an Fragen und Antworten – wie es sich für einen Podcast nunmal gehört. Ich hoffe, ihr hattet Spaß beim Anschauen.Wer noch Fragen hat, kann sie gerne auch hier stellen. Ich gebe mir Mühe, alle zu beanworten.
Apropos Fragen und Antworten: Kommentare gab es sowohl bei meinem Artikel auf heise+ als auch bei der #heiseshow Seite als auch auf YouTube zuhauf – teilweise mehrere Hundert. Davon sind natürlich nicht alle fachlich ernstzunehmen, aber zumindest ist etwas Regung drin. Sehr gut!
An analysis of some falsified leap second warnings that appeared in November 2021 on public NTP servers out of the NTP Pool Project.
Introduction
When using time scales such as UTC that do not use daylight saving time, each day has a strict 60 x 60 x 24 = 86400 seconds pattern. But due to variation in the earth’s rotation, the last day of a month may have 86399 or 83401 seconds; these are caused by negative/positive leap seconds. Leap seconds are announced by IERS six months prior to the event. All previous leap seconds have been positive and occurred on the last day of December or June. The most recent leap second as of now occurred on December 31, 2016.
Unexpected Leap Second Warning
On November 27, 2021, several public Network Time Protocol (NTP) servers began advertising “LI=1” (leap indicator), meaning that a positive leap second is coming at the end of the day. This was odd since no leap second was scheduled during 2021. Leap seconds normally occur only at the end of June 30 or December 31, UTC. Of the thousands of NTP servers I am monitoring, none had been advertising LI=1 in recent months.
But this wasn’t the end of the warnings. At 2021-11-30 00:00 a largely different set of NTP servers began sending LI=1. Some NTP software keeps an internal leap-second-pending flag and delays leap second processing until the last day of the current month. Following is the count of NTP servers as recognized by my monitoring system:
2021-11-27 LI=1 warning:
72 servers total
53 stratum 1 (all indicated reference ID=GPS); LI=1 was steady when it occurred
17 stratum 2
2 stratum 3
2021-11-30 LI=1 warning:
86 servers total (stratum varied for some servers)
A number of servers had leap indicators that changed from 0 to 1 and back again. Only four stratum 2 NTP servers were common in the November 27 and November 30 sets.
Leap Second Execution
In addition to signalling a pending leap second, many of these servers actually performed the positive leap second procedure; the last minute of the day had 61 seconds. This caused a 1-second time of day difference from actual UTC.
2021-11-28 00:00:00: For most of these NTP servers, the error was corrected after 1 second; during the one-second interval, the time-of-day was frozen at 00:00:00. Eight servers were in error by 1-second for between two and eight minutes. The 1-second error persisted on one server for 00:39:26.
2021-12-01 00:00:00: The duration of the 1-second time of day difference was generally longer, persisting for up to 01:22:31.
Affected Clients
As part of a study on unwanted high-rate NTP request bursts, client NTP requests were regularly recorded on several NTP servers including the client’s leap indicator.
NTP Server Location
Fraction of NTP clients sending LI=1
just before 2021-12-01 00:00 UTC
(based on one 20 minute sample for each server)
Wellington, NZ
0.025% overall, 130 clients affected
San Francisco, US
0.294% overall, 7011 clients affected
London, UK
0.635% overall, 4791 clients affected
All three of these servers had LI set to 0, which is correct. It seems that clients with LI=1 were using one or more of the affected NTP servers.
The New Zealand server was continuously collecting logs which allowed the number of LI=1 clients to be tracked throughout these two days.
Miroslav Lichvar (who maintains chrony) commented: “I suspect the actual percentages were likely even larger as most clients don’t put their leap state in their requests.“
Common Thread – Impacted NTP Servers
Among the NTP servers advertising LI=1 on 2021-11-27 was one of my home servers, an inexpensive, high-performance stratum 1 LeoNTP. This was seen on Twitter:
⏲️ LeoNTP users – please update FW to v1.24 to avoid erroneous Nov 2021 leap second warning: https://t.co/gvbF90VLgF Ublox GPS chipset we use [incorrectly] reports leap second event date as GPS week 2185 (Nov 2021) instead of 1929 (Dec 2016.) pic.twitter.com/ZWEkuAB5U2
Upon applying the new firmware my LeoNTP server correctly set LI=0.
At least 42 of the Stratum 1/GPS servers advertising LI=1 on 2021-11-27 were LeoNTP units. Little is known about the other 16. None of these servers showed incorrect behaviour on 2021-11-30.
I estimate that these 42 LeoNTP servers were receiving in excess of 30,000 requests/second on 2021-11-27. These servers were likely providing time to hundreds of thousands and possibly millions of clients, all were being told that a leap second was coming. It isn’t known how many of those clients executed a leap second on 2021-11-28 00:00:00. The detailed server logs indicate that a number did execute the leap second and were in error by one second for some minutes.
Event Summary and Fallout
November 27, 2021:
53 NTP stratum 1 servers, including 42 LeoNTP units, begin advertising LI=1. A fix was available from the manufacturer but was not installed on many public servers.
At midnight (2021-11-28 00:00:00), most of these servers incorrectly executed a leap second procedure resulting in a short (typically one second) time of day error.
The number of clients executing an unplanned leap second procedure is unknown.
November 30, 2021:
86 NTP servers, largely different from the November 27 set, began advertising LI=1 at various times during the day. The leap indicator was erratic on some servers.
At midnight (2021-12-01 00:00:00), many of the servers executed an unwanted leap second procedure. A one-second time offset was present for up to 1.3 hours.
The number of clients executing an unplanned leap second procedure is unknown.
A few messages were exchanged in Time-nuts and NTP mailing lists. Otherwise, this event apparently passed unnoticed.
Déjà Vu
The erroneous leap second warning was anticipated.
The most recent leap second was 2016-12-31 (MJD 57753). 8 bits or 256 weeks later […] will be 2021-11-27 (MJD 59545). So shortly before, on, or after that date it is possible a faulty GPS receiver will misrepresent a leap second or miscalculate UTC.
Just a few weeks ago on 27 November 2003 a 256-weeks-since-the-last-leap-second timing glitch occurred in some GPS receivers. […] Fortunately, because the hour was 62 o’clock, simple error checking in any host software would reject the erroneous message.
The November 2021 incident had only a 1-second error and was simply accepted by many NTP clients.
Background: Leap Second Dissemination
Leap seconds typically occur on the last day of June or December. Leap seconds can occur in other months, but that has never happened. Bulletin C, published by the International Earth and Rotation Reference Systems Service (IERS) twice per year, gives the upcoming leap second status. The last leap second was December 31, 2016. No leap second was announced for 2021.
Upcoming leap second announcements are redistributed via GPS, NIST’s WWV/WWVB and ACTS service, PTB’s DCF77 and other mechanisms, including NTP. Rather than depending on possibly noisy upstream sources, many use a leap second table as a definitive source of past and upcoming leap seconds.
Leap seconds can only occur on the last day of a month, some NTP software does not enforce that rule.
Leap seconds have triggered many problems. Apparently the impact of the errant November 2021 leap second was insignificant. There is strong sentiment for eliminating leap seconds but the required decisive action has not happened.
I just had a hard time figuring out that a network routing setup was not working due to a correctly enforced IP Spoofing protection on a Palo Alto Networks firewall. Why was it a hard time? Because I did not catch that the IP spoofing protection kicked in since there were no logs. And since we do log *everything*, a non-existent log means nothing happened, right? Uhm, not in this case. Luckily you can (SHOULD!) enable an additional thread log on the Palo.
The exception proves the rule. That is: blocks/drops that are enforced with these options are NOT logged in any way within the GUI:
The only way to find some drops, e.g., spoofed IP addresses (aka unicast reverse path forwarding), was the global counters along with an appropriate packet filter (from the GUI at Monitor -> Packet Capture):
weberjoh@pa(active)> show counter global filter packet-filter yes | match spoof
flow_dos_pf_ipspoof 1908 0 drop flow dos Packets dropped: Zone protection option 'discard-ip-spoof'
Investigating IP Drops (amongst others)
With PAN-OS 8.1.2, Palo Alto Networks released a new feature: “Logging of Packet-Based Attack Protection Events“. With this feature, all (?) protections are logged in the threat log which is accessible through the GUI.
You have to enable this feature on every single firewall in question in order to see those logs in the threat log:
set system setting additional-threat-log on
Some notes about this CLI command:
it does not require a reboot -> it is live instantly
it is persistent, that is: it survives a reboot of the firewall
it is NOT part of the configuration file -> if you’re doing an RMA or a tech refresh you have to set it again!
it is NOT synced within an HA cluster -> you have to enable it on every single firewall
you can verify whether or not this logging feature is enabled with the following command:
show system state filter cfg.general.additional-threat-log
However, please enable it carefully to not overwhelm your logs. ;)
This is how I’ve done it on one of my firewalls. Checked it, enabled it, checked it again:
weberjoh@pa(passive)> show system state filter cfg.general.additional-threat-log
'cfg.general.additional-threat-log': NO_MATCHES
weberjoh@pa(passive)>
weberjoh@pa(passive)>
weberjoh@pa(passive)> set system setting additional-threat-log on
weberjoh@pa(passive)>
weberjoh@pa(passive)>
weberjoh@pa(passive)> show system state filter cfg.general.additional-threat-log
cfg.general.additional-threat-log: True
weberjoh@pa(passive)>
And this is what the protection against IP spoofs looks like in the threat log:
By the way: Google pointed me to the solution on Reddit respectively Palo Altos LIVEcommunity. Meanwhile, I was confused by a new feature from PAN in a non .0 PAN-OS version. Anyway, some more feature requests to Palo Alto Networks:
Feature request #1: enabling/disabling this feature through the GUI just like any other feature.
Feature request #2: adding a big sign at the zone protection profile about these probably not logged blocks.
Palo Alto firewalls have a nice packet capture feature. It enables you to capture packets as they traverse the firewall. While you might be familiar with the four stages that the Palo can capture (firewall, drop, transmit, receive), it’s sometimes hard to set the correct filter – especially when it comes to NAT scenarios. (At least it was hard for me…)
I am using the packet capture feature very often for scenarios in which the IP connections are in fact working (hence no problems at the tx/rx level nor on the security policy/profile) but where I want to verify certain details of the connection itself. I’m simply using the Palo as a capturing device here, similar to a SPAN port on a switch. (Yes, I’m aware of all disadvantages of not using a real TAP and a real capture device.) In the end, I want a single pcap which shows all relevant packets for a client-server connection, even if NAT is in place. Wireshark should be able to correlate the incoming/outgoing packets into a single TCP stream. Furthermore, I definitely want to use a filter to limit the amount of captured packets. This is how I’m doing it:
I am using a PA-220 with PAN-OS 10.0.10. The screenshots are from Wireshark version 3.6.5. For the sake of simplicity, I’m only using IP addresses in the filters, not ports. To my mind, this is a reasonable tradeoff between “filtering but not too complicated”. I’m always enabling the “pre-parse match” checkbox. (Has anyone ever had a case where this checkmark saved four life? Please write a comment if so!) In addition, I’m always capturing at all four stages. For all the following tests, I did a ping followed by an SSH connection attempt.
This was my test setup:
Scenario 1: End-to-End Communication w/o NAT
Ok, that’s an easy one. Simply use a single filter statement for your client -> server. Returning traffic is captured automatically. (I wasn’t sure about this for a long time.) No need for a second statement such as server -> client.
Capturing all four stages, the firewall stage has everything captured, hence Wireshark is able to correlate the echo-request/-replies as well as the whole TCP/SSH session. Never mind of the VLAN tag that is present on only one side of the connection since my client network is within VLAN 69 at this point while the other interface is untagged.
Scenario 2: Internal Client -> External Server with outgoing SNAT/PAT aka “Dynamic IP And Port”
Now here’s the trick: I’m still using a single filter statement with the internal RFC1918 IPv4 address as the source and the public server IPv4 address as the destination:
Looking at the firewall, receive, and transmit stage, none of them is complete. The firewall stage only lists the outgoing direction (RFC1918 -> dest) since the returning traffic is still NATted, hence the filter is not working; the receive stage captured the outgoing traffic (RFC1918 -> dest) and the returning, but NATed (dest -> SNAT), hence no correlation in Wireshark as well; and the transmit stage captured only the returning traffic (dest -> RFC1918):
BUT: merging the firewall & the transmit stages gives a perfectly correlated pcap. Yee-haw!
You can do this merge directly within Wireshark. Simply open the first capture, then File -> Merge… and select the second one. (Unfortunately, this merge trick with Wireshark is only working for two pcaps. :( If you have more than two to merge, you have to use mergecap.exe.)
In the end, this is it: a single view in Wireshark, ping request/replies and a single and complete TCP stream:
(I also tried other filter settings such as this:
which did not lead to a single capture file from a single stage to have all streams correlated correctly. Hence I’m staying with the upper approach.)
If you prefer to have the “SNAT IP -> server IP” in the capture, you can use the same trick but with the following filter, which exactly matches the SNAT -> dest IPs:
Gives this:
Scenario 3: Incoming DNAT Connection
Let’s have a look at the classical DNAT scenario: You’re hosting a server with internal RFC1918 addresses with a DNAT policy. Now the client is on the Internet and your server on the internal network. Again, two working filter setups.
1) public client -> public DNAT:
Merging the firewall and the transmit stage:
2) public client again -> RFC1918 address:
Merging fw & tx:
Conclusion
I’m still not sure whether this is the best way to do it. If you have better filter ideas, please write a comment. However, having this post as a reminder for myself, I’m fine with it.
By the way: With IPv6, we won’t have this problem with NAT anymore. ;)
Angreifer verwenden gern Ping und Traceroute, um Server im Internet ausfindig zu machen. Das bringt viele Security-Admins in Versuchung, den Ping- und Traceroute-Verkehr mittels ihrer Firewall in ihrem Netz zu unterbinden. Doch damit behindern sie nur die Arbeit von Server-Administratoren, denn es gibt noch viel mehr Möglichkeiten, Server aufzuspüren.
Diesen Artikel habe ich initial für die c’t geschrieben, wo er im Heft 04/2018 erschienen ist. Als Autor habe ich dankenswerterweise die Erlaubnis, ihn hier auf meinem Blog ebenso zu veröffentlichen. Eine Übersicht der von mir geschriebenen c’t Artikel gibt es hier.
Die Kommandozeilen-Tools Ping und Traceroute, die zu jedem modernen PC-Betriebssystem gehören, sind sowohl bei Angreifern als auch bei Server-Administratoren beliebte Werkzeuge – sie lassen sich leicht über Skripte automatisieren und liefern so in kurzer Zeit einfache Antworten auf die Frage: Läuft unter einer bestimmten IP-Adresse ein Server oder nicht? Wenn ja, dann sind Server-Administratoren zufrieden, während Angreifer die Ärmel hochkrempeln, um den Server näher zu untersuchen und möglichst zu übernehmen.
Genau Letzteres wollen Security-Admins unterbinden und manche richten dann eine vermeintliche Totalblockade ein: Sie unterbinden mittels Firewall-Regeln jeglichen Ping- und Traceroute-Verkehr zum und vom Server. Doch das sind Placebo-Regeln – sie beruhigen lediglich, ohne die Sicherheit zu erhöhen und behindern aber das Monitoring des Servers. Denn öffentliche Server lassen sich auch ohne Ping leicht identifizieren.
Dafür gibt es eine Handvoll von Universal- und Spezialwerkzeugen, deren Konzepte und Funktionen wir detailliert vorstellen. Wir stellen Ping und Traceroute an den Anfang, weil sich darüber grundlegende Konzepte am einfachsten erklären lassen. Danach folgen Monitoring-Tools auf Applikationsebene, für die Traceroute mit etwas Know-how ebenfalls nutzbar ist. Alle optionalen Tools finden Sie über ct.de/y8pp.
Ping- und Traceroute-Grundlagen
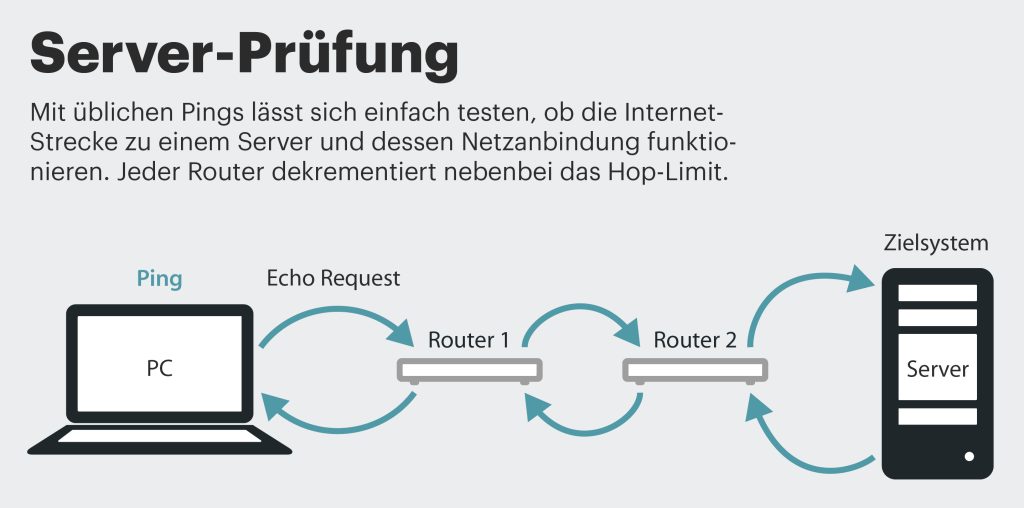
Der Ping-Befehl ist ein simples Tool, mit dem sich die Netzwerkverbindung zu einem Gerät testen lässt. Die Anfrage des Senders (Echo Request) und die Antwort des Empfängers (Echo Reply) sind in der Protokollspezifikation RFC 792 definiert (Internet Control Message Protocol, ICMP). Wenn der Absender des Ping-Kommandos ein Reply-Paket vom Zielsystem erhält, bedeutet das, dass die Netzwerkstrecke zur angefragten IP-Adresse funktioniert. Zudem liefert Ping die Signallaufzeit für den Hin- und Rückweg. Die Laufzeit (Latenz) ist ein einfaches Maß für die Reaktionsgeschwindigkeit des Servers. Je kürzer die Latenz, desto zufriedener der Admin und die User.
Auf Windows- und Unix-Systemen lautet der Befehl schlicht
ping. Darauf folgt die Zieladresse, also beispielsweise
ping heise.de. Der Befehl gibt pro Antwortpaket eine Zeile aus. Darin sind die Signallaufzeit in Millisekunden sowie die Anzahl der Zwischenstationen auf dem Pfad zum Ziel aufgeführt (Hops bei IPv6, TTL bei IPv4, siehe Kasten „Unterschiede zwischen IPv6 und IPv4“).
Wenn auf Windows und Linux beide Internet-Protokolle konfiguriert sind (IPv4 und IPv6, also Dual-Stack), schickt das Betriebssystem den Request per IPv6 ab. Mit den Optionen
-6 und
-4 erzwingt man eines der beiden Protokolle. Ältere Linuxe nutzen von Haus aus IPv4; für Pings per IPv6 verwenden sie
ping6.
Der Windows-Befehl sendet in der Grundeinstellung vier Echo-Anfragen und stoppt dann. Der Linux-Befehl schickt Anfragen kontinuierlich, bis man ihn mittels Strg+C beendet. Alternativ lässt sich die Anzahl mit der Option
-c begrenzen (z. B.
ping -c 3 für genau drei Pings).
Wenn man auf Ping-Requests keine Antworten erhält, ist es zunächst offen, woran das liegt. Möglicherweise antwortet der Host nicht, aber es ist auch nicht auszuschließen, dass eine Firewall auf der Strecke zum Ziel den ICMP-Request nicht durchlässt. Das kann man mit dem Tool Traceroute genauer untersuchen. Traceroute nutzt den IP-Parameter Hop-Limit (bei IPv4 Time To Live, TTL genannt), um Antworten von bestimmten Routern zu erhalten, die den Pfad zum Host bilden.
Auf Windows lautet der Befehl
tracert, auf Linux und macOS
traceroute; danach folgt die Zieladresse. Der Windows-Befehl nutzt für die Pfadanalyse normalerweise ICMP-Pakete vom Typ Echo Request, also Ping-Pakete. Linux schickt hingegen UDP-Pakete mit Zielports ab 33434 aufwärts. Setzt man die Option
-I, schaltet man auf Linux auf den Versand von ICMP-Echo-Requests um. Dafür sind Root-Rechte erforderlich.
Eigentlich ist das Hop-Limit als Schutzfunktion und Warnmechanismus gedacht: Falls Netzbetreiber versehentlich eine Routing-Loop konfiguriert haben, würden Pakete, die in der Loop landen, sinn- und endlos darin kreisen. Deshalb werden IP-Pakete normalerweise mit einem Hop-Limit von zum Beispiel 64 oder 128 auf die Reise geschickt und jeder Router, der es empfängt, muss das Hop-Limit um 1 dekrementieren, bevor er es weiterreicht. Ist Hop-Limit 0 erreicht, darf ein Paket nicht weitergereicht werden, der Router muss es verwerfen. Zugleich sollte er den Absender des Pakets darüber mit der ICMP-Meldung „Time Exceeded/Hop Limit exceeded“ informieren. Ein Netzwerk-Admin kann dann anhand der Fehlermeldung der Ursache auf den Grund gehen.
Traceroute setzt das Hop-Limit ein, um Antworten von Routern auf dem Pfad zum Zielsystem zu erzwingen, die ein IP-Paket normalerweise stillschweigend weiterreichen. Dafür schickt der Befehl mehrere IP-Pakete zum Ziel. Er startet mit Hop Limit 1 und inkrementiert den Wert schrittweise um 1. Der erste Router, der das Paket mit dem Hop-Limit 1 empfängt, dekrementiert das Hop-Limit und muss es gleich verwerfen und dem Absender „Time Exceeded“ melden. Traceroute findet in der Antwort die IP-Adresse des ersten Routers und führt diese oder den DNS-Namen, den es per Reverse-Lookup zu ermitteln versucht, mitsamt der Latenzangabe in einer Zeile der Ausgabe auf.
Mit dem zweiten Paket (Hop-Limit 2) wird der zweite Router veranlasst, eine Fehlermeldung zu schicken. So geht es weiter, bis das Ziel erreicht ist. Pro Hop-Limit sendet Traceroute typischerweise drei Pakete.
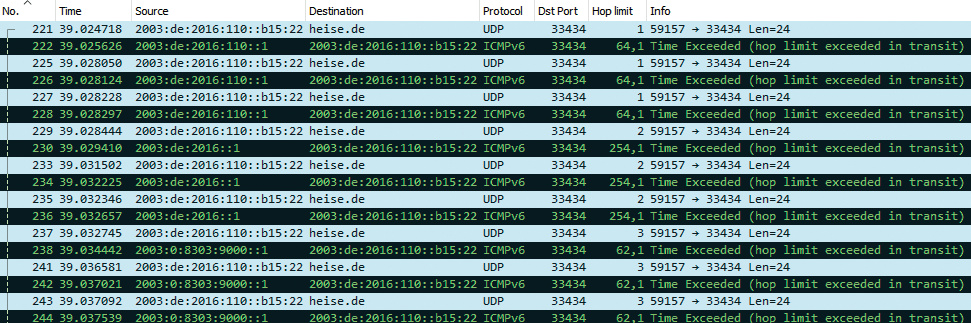
Traceroute in Wireshark-Ansicht: Mit dem IP-Analyse-Tool sind neben dem Trace zu heise.de noch weitere IP-Details zu sehen, darunter etwa, dass das Hop-Limit-Feld nicht nur in den zum Ziel abgeschickten Paketen belegt ist, sondern auch in den Antwortpaketen der Router.
Im Beispiel „Traceroute in Wireshark-Ansicht“ ist das Ergebnis einer IPv6-Pfadanalyse zu heise.de im Netzwerkmonitor Wireshark zu sehen. Der Befehl sendet UDP-Pakete an Port 33434 (grau unterlegt). Darauf folgen die empfangenen Pakete (schwarz unterlegt). Quelle und Ziel (Source, Destination) der Traceroute-Pakete sind gleich, lediglich das Hop-Limit erhöht sich alle drei Pakete um 1. Die Antworten kommen per ICMPv6 und sind vom Typ „hop limit exceeded in transit“. Im Beispiel sind je drei dieser Meldungen von den ersten drei Routern entlang des Pfades zu sehen.
Detail am Rande: Auch die von den Routern gesendeten ICMPv6-Pakete haben ein Hop-Limit. Der erste und der dritte Router haben den Wert auf 64 gesetzt, der zweite auf 255. In der Ausgabe sind beim zweiten und dritten niedrigere Werte zu sehen (254 und 62), weil das Hop-Limit der Pakete unterwegs dekrementiert worden ist.
Wenn Traceroute innerhalb von 5 Sekunden keine Antwort von einem Router auf der Strecke erhält, markiert es diesen mit einem Stern (*). Diese Frist lässt sich mit der Option
-w ändern. Wenn ein Router keine Fehlermeldung schickt, kann das an drei Dingen liegen: Der Admin hat diese Funktion deaktiviert, die Management-Plane des Routers ist überlastet oder eine Firewall blockiert die entsprechenden Pakete.
Server und DMZ: Öffentliche Server sind in Firmen oft Teil größerer Netze und stehen aus Sicht des Breitband-Routers irgendwo im LAN und aus Sicht der Firewall in einer DMZ (Demilitarized Zone): So sind sie aus dem Internet erreichbar, aber per Firewall-Regel vom übrigen Verkehr im LAN abgeschottet. Die Absicht ist, den Schaden möglichst auf den Server zu begrenzen, falls er mal kompromittiert wird.
Applikations-Ping
Anstatt nur die IP-Verbindung zu einem Server zu prüfen (Schicht 3 im OSI-Modell), lässt sich auch der Server-Dienst mit einfachen Kommandos prüfen – das entspricht Pings auf Applikationsebene (Schicht 7 des OSI-Modells). Dabei verschickt ein Kommando echte Anfragen für einen Service, beispielsweise HTTP oder SMTP. Weil sich die Befehle über Skripte automatisieren lassen, lässt sich fortlaufend prüfen, ob etwa ein Webserver läuft, ohne in einem Browser wiederholt die F5-Taste zu drücken oder den Reload-Button zu klicken.
Die meisten Layer-7-Dienste setzen auf TCP oder UDP auf. Entsprechend verwenden auch die Tools TCP oder UDP. Weil UDP verbindungslos arbeitet, kann für den Test schon ein UDP-Paket genügen. Für TCP ist der übliche Drei-Wege-Handshake „SYN, SYN-ACK, ACK“ erforderlich.
Für den Test von Webservern ist das Tool
httping gebräuchlich. Es sendet im Sekundentakt HTTP-Requests an den Zielserver. Ohne weitere Optionen fragt es nur den Header des Wurzelverzeichnisses „/“ ab (HEAD).
Der Befehl ist in diversen Linux-Repositories enthalten, beispielsweise Ubuntu. Oft sind die dort enthaltenen Versionen veraltet, weshalb wir empfehlen, die aktuelle Fassung der Software manuell zu installieren (zurzeit ist das Version 2.6):
sudo apt-get install libncursesw5-dev libssl-dev libfftw3-dev gettext
git clone https://github.com/flok99/httping.git
cd httping/
make
sudo install
Mac-User finden httping über die optionalen Paketmanager MacPorts und brew. Windows-Versionen kann man von der Seite des Entwicklers beziehen.
Im Beispiel „Webserver-Test“ ist zu sehen, wie httping den Webserver heise.de prüft. In der Ausgabe liefert es zum Beispiel die Latenz und den aktuellen Statuscode des Servers (im besten Fall ist das „200 OK“). Pro Zeile baut das Tool eine vollständige TCP-Verbindung gefolgt von einem HTTP-HEAD-Request auf. Jede Antwort belegt, dass die Internetverbindung sowie der Webserver grundsätzlich funktionieren.
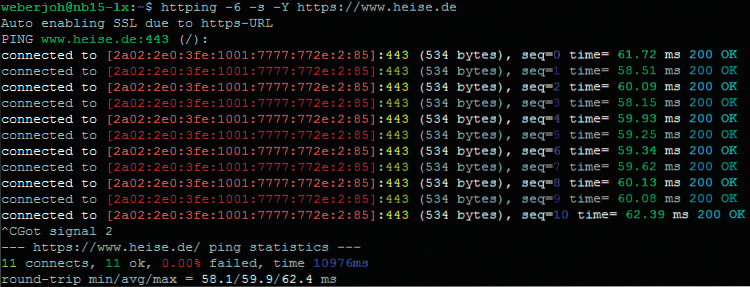
Webserver-Test: Mit httping testen Sie die Erreichbarkeit eines Webservers. Unter anderem lässt sich damit die Signallaufzeit ermitteln und der aktuelle Status des Webservers auslesen.
Um TLS-gesicherte Webseiten anzupingen, stellen Sie der Zieladresse https:// voran, beispielsweise
httping https://heise.de. Mit den Optionen
-s -Y lässt sich der HTTP-Status-Code farbig unterlegen.
Das Tool ist für gängige HTTP-Optionen ausgelegt. Es eignet sich auch für HTTP- und HTTPS-Verkehr über einen Proxy und kann die HTTP-Authentication prüfen.
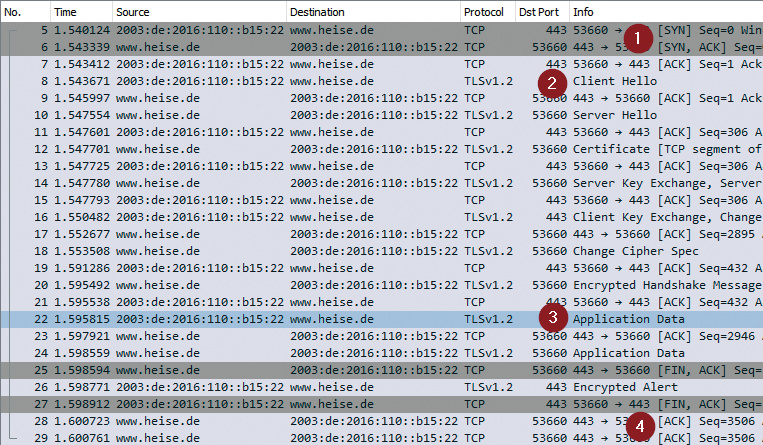
HTTPS-Test: Mit dem optionalen Befehl https lassen sich Webserver auch TLS-gesichert ansprechen. Gut zu erkennen ist, dass der Verbindungsaufbau mehrere Schichten einbezieht, sodass weit mehr Traffic fließt als bei einem Ping-Test.
Bei einer TLS-Verbindung zu einem Webserver (siehe HTTPS-Test) gehen ganze 25 Pakete über das Internet. Zuerst läuft ein vollständiger TCP-Handshake ab (Phase 1, in Wireshark grau markiert), dann die TLS-Aushandlung (Phase 2). Dann wird der HTTP-Request gesendet (Phase 3). Zum Schluss baut das Tool die TCP-Sitzung ordnungsgemäß ab (Phase 4). Dennoch dauert ein Durchlauf bei gängigen Zielen in Deutschland nicht länger als 100 ms.
DNS-Server-Prüfungen
Mit dem in Python geschriebenen Tool
dnsping lässt sich die Erreichbarkeit und Grundfunktion von DNS-Servern per DNS-Anfrage prüfen (Query). In der Grundeinstellung befragt dnsping den ersten konfigurierten Resolver nach einem A-Record des angegebenen Hosts. In der Ausgabe führt das Tool die Latenzen auf. Für die Abfragen verwendet es DNS-gemäß UDP, sodass für Hin- und Rückweg je ein Paket genügt.
Dnsping ist Teil der „DNS Diagnostics and Performance Measurement Tools“, kurz DNSDiag. Für Windows und macOS sind Binaries auf GitHub erhältlich. So installieren Sie es auf Linux:
Für einen einfachen DNS-Ping an Ihren DNS-Resolver reicht die Angabe eines Hosts – etwa so:
./dnsping.py heise.de. Zusätzlich können Sie sich die DNS-Antwort ausgeben lassen
-v, den anzufragenden DNS-Resource-Record festlegen
-t <type> (standardmäßig A), den DNS-Server angeben
-s <server> oder das Internet-Protokoll bestimmen
-6/-4.
Das DNS-Protokoll kann alternativ TCP nutzen. Das ist bei Antworten erforderlich, die für UDP zu groß sind. Um eine TCP-Anfrage zu senden, setzt man die Option
-T. Kommt die erwartete DNS-Antwort an, heißt das, dass Firewall und DNS-Resolver DNS-TCP-Pakete durchlassen, also korrekt konfiguriert sind.
Verwenden Sie in Ihrem Netzwerk einen DNS-Resolver, so verifizieren Sie mit diesem Tool dessen Verfügbarkeit und ermitteln die (grobe) Latenz. Im Heimbereich stellt jeder Router einen solchen Resolver bereit. So prüfen Sie, ob er funktioniert:
./dnsping.py -s 192.168.xxx.1 ct.de
Der Parameter
-s 192.168.xxx.1 legt die IP-Adresse des Routers fest. Bei den verbreiteten Fritzboxen ist das normalerweise 192.168.178.1, bei Speedports 192.168.2.1.
Nach dem gleichen Muster lassen sich öffentliche DNS-Resolver wie Googles Public-DNS (2001:4860:4860::8888 bzw. 8.8.8.8) oder OpenDNS testen (2620:0:ccc::2 bzw. 208.67.222.222). Anhand der Antworten lässt sich die Geschwindigkeit der DNS-Server vergleichen. Schnelle DNS-Server sind vorzuziehen, weil je umfangreicher Web-Seiten sind, desto mehr DNS-Anfragen geschickt werden müssen. Und je eher die DNS-Antwort da ist, desto eher kann ein Browser die jeweilige IP-Adresse aufrufen.
Auch aus dem Internet erreichbare autoritative DNS-Server lassen sich per dnsping testen. Geben Sie als Ziel die öffentliche IP-Adresse des Servers an und fragen Sie ihn nach einer der Domains, die er selbst verwaltet. Beispiel: Für ebay.de ist der DNS Server „a1.verisigndns.com“ zuständig.
Ihr eigener autoritativer DNS-Server sollte aus Sicherheitsgründen nicht auf Anfragen für sonstige Domains wie „heise.de“ antworten, da er dann als öffentlicher DNS-Resolver missbraucht werden kann. Für die Prüfung der DNSSEC-Validierung von Resolvern gibt es im gleichen Toolkit das Kommando
dnseval. Weitere Details zu Tools aus der DNSDiag-Suite liefert die Webseite des Entwicklers (siehe ct.de/y8pp).
Mail-Server-Prüfungen
Um die Funktion eines SMTP-Servers fortlaufend zu prüfen, kann man das Kommando
smtpping verwenden. Das Kommando ist via GitHub für Windows, macOS und Linux erhältlich und verschickt wie ein Mail-Client komplette E-Mails, liefert aber zusätzliche Statusinformationen.
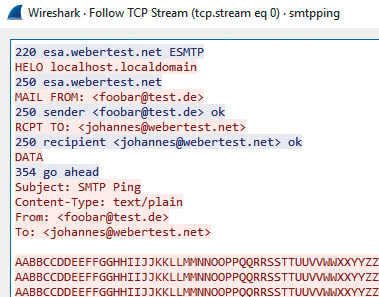
SMTP in Wireshark: Die Meldungen des smtpping-Tools sind rot dargestellt, die Antworten des SMTP-Servers in Blau. Das Testprogramm hat eine Mail mit dem Betreff „SMTP Ping“ eingereicht“.
Wenn Sie dieses Tool in ein Skript einbauen, sollten Sie keine kurzen Test-Intervalle festlegen, weil SMTP-Server das wie eine SPAM-Welle auffassen können – im Weiteren blockieren SMTP-Server die Mail-Annahme von derart aufgefallenen IP-Adressen (Gray- oder Blacklist). Ein Beispiel für einen SMTP-Test sieht so aus:
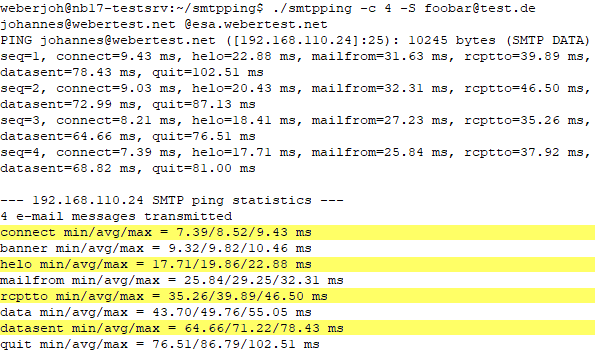
Der Parameter
-c <count> legt die Anzahl der Prüfungen pro Programmstart fest. Im obigen Beispiel sind es vier Durchläufe. Darauf folgen die Absenderadresse
-S <adresse> und die Empfängeradresse. Wird kein SMTP-Server per
@<server> angegeben, schickt das Tool die Mail an die Adresse, die im MX-Record der jeweiligen Empfänger-Domain eingetragen ist.
Damit ein SMTP-Test funktioniert, muss der testende Rechner eine statische öffentliche IP-Adresse verwenden. Mails, die von dynamischen öffentlichen IP-Adressen eingereicht werden, verarbeiten SMTP-Server normalerweise nicht. Das ist eine seit Langem übliche Vorkehrung gegen den SPAM-Versand von Malware-befallenen privaten Rechnern.
Falls der Test-Rechner über eine dynamische öffentliche IP-Adresse mit dem Internet verbunden ist, kann man ersatzweise SMTP-Relays als Vermittler verwenden. Dafür trägt man am Ende der Befehlszeile ein @-Zeichen gefolgt von der IP-Adresse des Relays ein (z. B. @198.51.100.10).
Mittels smtpping senden Sie eine komplette E-Mail an einen SMTP-Server. So lässt sich nicht nur die Verfügbarkeit prüfen, sondern auch die Geschwindigkeit messen. Bei der Anzahl der Testdurchläufe ist Vorsicht geboten.
Smtpping führt in seiner Ausgabe auch Antwortzeiten des SMTP-Servers für jede der SMTP-Kommunikationsphasen auf. Sie sind in sechs Abschnitte unterteilt (connect, helo, mailfrom … ). Eine ungewöhnlich lange Verarbeitungsdauer einer Phase kann ein Hinweis auf einen Fehler sein.
Traceroute-Spezialitäten
Manche Security-Admins sperren den Ping-Verkehr zu öffentlichen Servern, die in ihrer DMZ stehen. Näher besehen bringt diese Sperrung bei einfachen Firewalls keine Security-Vorteile, denn der Server lässt sich von außen dennoch leicht identifizieren.
Das geht per Layer-4-Traceroute (engl. Layer Four Traceroute, LFT). Dafür genügt es, ein Päckchen an einen spezifischen TCP- oder UDP-Port eines Servers zu schicken. Dabei handelt es sich tatsächlich um gängige TCP-SYN-Pakete, und schlichte Firewalls lassen sie daher passieren. So kann man einen TCP-Aufbau mit einem Webserver simulieren, indem man ihm ein Päckchen an Port 80 schickt – das sieht aus wie der Beginn einer Browsing-Session.
Das hat Folgen für die Sicherheit der Infrastruktur hinter dem Internet-Router: Wenn dahinter auf dem firmeninternen Pfad zum Webserver Router stehen, dann lassen sie sich anhand von Paketen identifizieren, deren Hop-Limit beim Empfang 1 beträgt. Sie müssen dann das Hop-Limit dekrementieren und im Normalfall dem Absender des Pakets mit „ICMP Time Exceeded“ antworten. Einfache, Port-basierte Firewalls erkennen in einem zurück zur Quelle wandernden ICMP-Päckchen keine Gefahr und lassen es passieren. So tröpfeln Informationen über den firmeninternen Routing-Pfad innerhalb der DMZ nach draußen.
Layer-4-Traceroute: Der Befehl verschickt pro Hop-Limit-Inkrement je drei TCP-SYN-Pakete an Port 443 der Zieladresse, hier www.heise.de.
Um solche speziellen Traceroutes zu starten, sind auf Linux Root-Rechte erforderlich. Mit der Option
-T schaltet man TCP ein,
-U steht für UDP. Einen Webserver spricht man auf Port 80 oder Port 443 per TCP an
-p <port>, einen DNS-Server auf Port 53 mit UDP. So testen Sie den HTTPS-Service von heise.de via IPv6:
sudo traceroute -6 -T -p 443 www.heise.de
Sie möchten den Routing-Pfad zu einem SMTP-Server ermitteln? Schicken Sie einen Layer-4-Traceroute auf den TCP-Port 25 des Servers und lassen Sie sich überraschen, welche Unterschiede im Vergleich zu einem herkömmlichen Traceroute auftauchen.
DNS und Man-in-the-Middle
Eine Besonderheit im Zusammenhang mit Traceroute stellt der DNS-Dienst dar. Wenn DNS-Anfragen und -Antworten wie üblich per UDP übertragen werden, findet kein Layer-4-Handshake statt. So lässt sich eine DNS-Anfrage in einem einzigen UDP-Paket stellen.
Entsprechend kann ein Router, eine Firewall oder ein Intrusion-Prevention-System nicht nur das UDP-Protokoll mit Zielport 53, sondern auch die DNS-Anfrage lesen (wird im Klartext übermittelt) und unliebsame Anfragen blockieren, wenn es der Diktatur gefällt. DNS-Antworten können zudem gezielt gefälscht werden, um etwa auf staatliche Warn-Seiten umzuleiten.
Solche Manipulationen kann man mittels speziellen Traceroutes aufdecken: Man verschickt DNS-Anfragen und schaut per Hop-Limit-Inkrement, wie sie behandelt werden. Neben dem Routing-Pfad zum DNS-Resolver lassen sich auch manche Man-in-the-Middle-Angriffe beziehungsweise DNS-Spoofing-Attacken aufdecken.
Manipulationen erkennt man daran, dass die DNS-Antwort nicht vom eigentlichen DNS-Resolver kommt, sondern von einem normalerweise transparenten Infrastruktur-Element, das auf dem Pfad vor dem Resolver sitzt.
Derartiges DNS-Spoofing kann aber auch gewünscht sein. So bieten moderne Firewalls und DNS-Appliances ein Feature namens „DNS Sinkholing“ an, bei welchem DNS-Anfragen an Malware-Domains gezielt mit einer Dummy-IP-Adresse beantwortet werden, um den Benutzer zu schützen.
Für solche speziellen Analysen enthält die Suite DNSDiag das Tool
dnstraceroute; auf Linux und Windows sind für die Ausführung Root-Rechte erforderlich. Testen Sie zuerst die Auflösung von gängigen Domains mit Ihrem üblichen DNS-Resolver:
sudo ./dnstraceroute.py heise.de
Wie bei dnsping kann man den zu befragenden DNS-Server mit der Option
-s <server> festlegen. Mit der Option
-t <type> wählen Sie aus, welchen Resource Record der DNS-Server liefern soll (A = IPv4-Adresse, AAAA = IPv6-Adresse, MX = Domain des Mail-Servers).
Grundlegende Firewall-Empfehlungen
Aus Security-Sicht ist eine globale Ping-Sperre im internen Netz unnötig bis schädlich. Der Nutzen des Ping-Befehls ist für Administratoren, die die Verfügbarkeit von Diensten gewährleisten sollen, sehr hoch. Zugriffe aus dem Internet in eine DMZ sind normalerweise erwünscht – aber es sollten nur Zugriffe auf die tatsächlich erforderlichen Ports erlaubt sein. Einem Layer-7-Ping steht ohnehin nichts im Wege und auch Layer-4-Traceroutes werden Antworten liefern, sofern Sie keine weiteren Vorkehrungen vornehmen.
Eine moderne Firewall kann einen TCP-Traceroute auf Port 443 von einem üblichen HTTPS-Verbindungsaufbau unterscheiden. Das ist die Grundlage, um das Ausspionieren von internen Routing-Pfaden zu unterbinden.
Daher dürfte die Security einer Firma nicht maßgeblich leiden, wenn ICMP-Pings von außen in die DMZ erlaubt sind. Es liegt auf der Hand: Wenn Ihr Webserver auf gängige HTTP- und HTTPS-Anfragen aus dem Internet antwortet, ist er ja ohnehin bekannt und ein ICMP-Ping verrät Angreifern nichts Neues. Das Gegenteil ist jedoch der Fall, wenn Ihr Server nicht über Standard-Ports erreichbar ist, sondern über spezielle, die nur bestimmte Nutzer kennen. Nur dann sollte man ICMP-Pings verbieten, weil sich dann ein verborgener Server mittels automatischer Abfragen schneller identifizieren lässt.
Zugriffe vom Internet in das LAN sind ohnehin tabu, egal ob für ICMP-Pings oder sonstigen Verkehr. Aber das haben Ihre Firewall-Administratoren hoffentlich schon immer so konfiguriert.
Neben klassischen Port-basierten Firewalls bieten „Next-Generation Firewalls“ zumindest für die Behandlung von Layer-4-Traceroutes sehr detaillierte Einstellungen. Beispielsweise erkennen sie sie unabhängig vom verwendeten Protokoll. Damit kann man sie einfach unterbinden und HTTPS weiterhin zulassen. Ein regulärer Web-Browser wird so Ihren Webserver wie gewohnt per TCP-SYN auf Port 443 erreichen. Ein Layer-4-Traceroute, der einen TYP-SYN auf Port 443 nur vortäuscht, scheitert hingegen. So bleiben interne Routing-Pfade von außen nicht einsehbar.
Unterschiede zwischen IPv6 und IPv4: Alle in diesem Artikel beschriebenen Tools können Sie sowohl für IPv6 als auch für IPv4 verwenden. Bei den damit erzeugten IP-Paketen gibt es aber Unterschiede.
Für die Anwendung der Tools spielt das zwar keine Rolle, sollten Sie jedoch spezifische Filter für tcpdump, Wireshark oder ähnliche Tools bauen, müssen Sie genau zwischen dem Standard-Internet-Protokoll (IPv6) und dem veralteten IPv4 unterscheiden: Während ein IPv6-Ping die ICMPv6-Typen 128 (echo request) und 129 (echo reply) verwendet, nutzt man bei IPv4 die ICMPv4-Typen 8 (echo request) und 0 (echo reply).
Auch unterscheiden sich die Time-Exceeded-Pakete, die Traceroute verwendet. Bei ICMPv6 sind diese vom Typ 3 Code 0, bei ICMPv4 handelt es sich um Typ 11 Code 0.
Außerdem wird das Hop-Limit nur in IPv6-Headern verwendet. In IPv4-Headern steht hingegen „Time to Live“ oder kurz „TTL“. Es ist auch gut, dass man sich bei IPv6 vom TTL-Begriff getrennt hat, denn er bezeichnet keine Zeiteinheit.
TCP- und UDP-Pakete sind hingegen bei IPv6 und IPv4 gleich. Beide verwenden grundsätzlich die Felder Source- und Destination-Port. Auch auf Applikationsebene gibt es keine Unterschiede. Ein HTTP-Request, der per IPv6 übertragen wird, sieht exakt so aus wie bei IPv4.
Haben Sie mal Netzwerkmitschnitte untersucht, ohne zu wissen, was genau Sie suchen? Mit Wireshark wird das leicht zu einer Odyssee: Das Analysewerkzeug filtert zwar fabelhaft, reagiert bei großen Datenmengen aber schnell zäh.
Was bei solchen Problemstellungen hilft ist: tshark! Ein Tool, mit welchem Sie auch große Packet Captures einfach anhand gängiger Kriterien durchforsten können.
Diesen Artikel habe ich initial für die c’t geschrieben, wo er im Heft 14/2019 erschienen ist. Als Autor habe ich dankenswerterweise die Erlaubnis, ihn hier auf meinem Blog ebenso zu veröffentlichen. Eine Übersicht der von mir geschriebenen c’t Artikel gibt es hier.
tshark ist ein Kommandozeilentool, das zu Wireshark gehört und dieselben Protokoll-Dissektoren mitbringt. So kann man Netzwerkmitschnitte (auch Traces oder Captures genannt) ebenso detailliert filtern wie mit Wireshark. Anders als dieses GUI-Werkzeug lässt sich tshark aber mit weiteren Shell-Tools verknüpfen, was ermöglicht, seine Ausgabe weiterzuverarbeiten. Das erleichtert beispielsweise, Verhaltensauffälligkeiten von Clients oder sporadisch auftretenden Fehlern auf die Spur zu kommen. Security-Beauftragte können auch prüfen, ob etwa eine Firewall anfällig für bestimmte Attacken ist.
Die Konzepte lassen sich leicht auch privat für allerlei Analysen nutzen, etwa um zu ermitteln, mit welchen Zielen im Internet das neue Smart-TV spricht. Mit den Ergebnissen speist man dann beispielsweise Filterlisten von Pi-hole & Co.
Am Anfang einer Analyse empfiehlt es sich, die in einem Trace steckenden Informationen auf das Wesentliche zu reduzieren: Man filtert nur die Inhalte bestimmter Paketfelder heraus und schreibt diese in eine neue Datei. Wie bei Wireshark lassen sich Informationen auch mittels der Display-Filter isolieren, denn tshark gibt sie zeilenweise im Terminal aus. Die Ausgabe sortiert man mit den Kommandos “sort” und “uniq”.
Voraussetzungen
Auf Linux bekommt man tshark als einzelnes Element per Paketverwaltung (Beispiel für Debian:
sudo apt-get install tshark). Windows- und macOS-Nutzer installieren tshark zusammen mit Wireshark vom Installations-Image des Herstellers.
Windows bringt zwar “sort” mit, aber “uniq” fehlt. Wenn Sie nicht ohnehin schon das Cygwin-Paket oder Microsofts Linux-Subsystem für Windows nutzen, können Sie sich deren Installation sparen: “uniq” steckt in der nicht mal 1 MByte kleinen Tool-Sammlung UnxUtils, die sich im Handumdrehen installieren lässt. Für ein natives Windows-Tool und gegen Microsofts Linux-Subsystem spricht übrigens auch, dass manche Backup-Programme derartige Installationen nicht sichern können.
Die UnxUtils wurden zwar letztmalig im Jahr 2003 aktualisiert. Zumindest uniq funktioniert aber auf Windows bis einschließlich Version 10. Laden und entpacken Sie das Archiv in den Ordner C:\Programme. Benennen Sie in diesem Verzeichnis die Datei sort.exe zu sort2.exe um, was Verwechslungen mit dem Windows-eigenen Befehl vermeidet. tshark liegt auf Windows typischerweise im Ordner C:\Programme\Wireshark. Auf macOS finden Sie tshark im Ordner /Applications/MacPorts/Wireshark.app/Contents/MacOS/tshark, auf Linux in /usr/bin.
Damit Sie auf Windows tshark und uniq ohne komplette Pfadangabe verwenden können, fügen Sie die zugehörigen Verzeichnisse den Windows-Umgebungsvariablen hinzu. Geben Sie im Startmenü die ersten paar Buchstaben von „Umgebungsvariablen für dieses Konto…“ ein und klicken Sie auf den Eintrag in der Trefferliste. Doppelklicken Sie im Bereich „Benutzervariablen“ auf das Feld „Path“ und fügen Sie die beiden Pfade nacheinander über die Buttons „Neu“ und „Durchsuchen“ hinzu (siehe Screenshot). Wenn Sie nun ein neues CMD-Fenster öffnen, sollten Sie tshark ohne Pfadangabe starten können.
Tastaturschoner: Die Kommandos von Wireshark und den UnxUtils lassen sich ohne vorangestellten Pfad aufrufen, wenn man diesen den Umgebungsvariablen hinzufügt.
Auf dem Mac genügt es, der Variablen PATH ein Unterverzeichnis des Wireshark-Ordners hinzuzufügen. Öffnen Sie dazu die Datei ~/.bash_profile mit einem Editor wie nano und ergänzen Sie diese Zeilen:
Unter Linux sind keine Pfaderweiterungen erforderlich.
tshark-Grundlagen
tshark steuert man mit einer Handvoll Kommandozeilenoptionen. Wir stellen kurz die wichtigsten vor und zeigen anschließend, wie man sie zu kompletten Befehlen zusammenfasst und mit weiteren Befehlen verkettet.
Wie Wireshark oder tcpdump kann tshark den ein- und ausgehenden Netzwerkverkehr Ihres PCs mitschneiden. Mit der Option
-i wählen Sie das Interface, dessen Verkehr Sie aufzeichnen wollen und mit der Option
-w Dateiname.pcap legen Sie die Ausgabedatei fest.
Fertige Aufzeichnungen kann man dem Programm mit der Option
-r Dateiname.pcap übergeben. Ohne weitere Parameter würde tshark aber nur den Inhalt des Tracefiles im Fenster herunterrattern. Die von Wireshark bekannten Display-Filter setzt man mittels der Option
-Y Filterausdruck ein. Beispielsweise filtert
-Y http.request alle HTTP-Anfragen heraus. Verschachtelte Filteraufgaben kann man in Hochkommata eingeschlossen übergeben. Für jedes gefilterte Paket gibt tshark einige Statusinformationen aus: Die laufende Nummer im Trace, den Zeitstempel, Source- und Destination-IP, Portnummer und Info. Der Clou: Mit der Option
-T fields -e Feldname extrahiert tshark Inhalte bestimmter Felder.
Um einige Anwendungen durchzuspielen, haben wir eine rund 55 MByte große Beispieldatei eines Smart-TV von LG vorbereitet, die sich gut für Übungen eignet. Sie finden sie hier.
Zunächst geht es darum, die von einem Smart-TV angesprochenen (unverschlüsselten) HTTP-Server zu finden. Dafür filtert man am einfachsten das Feld http.host heraus:
-T fields -e http.host. tshark gibt damit jeden Treffer in einer separaten Zeile entsprechend der Reihenfolge im Tracefile aus. Um mehrere Felder zu filtern, setzt man die Option
-e Feldname mehrmals hintereinander.
Um weitere Display-Filter oder Feldnamen anzuwenden, testen Sie sie zunächst in Wireshark am selben Tracefile. Syntaxfehler stellt die Software rot hinterlegt dar. Wenn der Filterausdruck korrekt ist, wechselt die Farbe auf Grün.
Im Wireshark-Beispiel (folgender Screenshot) ist zu sehen, dass wir die UPnP-basierte Multicast-Kommunikation ausblenden:
http.host and not ip.dst == 239.0.0.0/8. Das empfiehlt sich, weil einige Geräte während der Aufzeichnung viele UPnP-Nachrichten verschickt haben. Diese tun aber nichts zur Sache und stören bloß. Außerdem ist zu sehen, wie ein Klick auf das zu untersuchende Feld (Mitte) Wireshark dazu bringt, den genauen Feldnamen anzuzeigen (unten). In diesem Fall blendet Wireshark http.host ein, also die Variable für den Namen des angesprochenen HTTP-Servers.
Übungsrunde: Um die Syntax von Display-Filtern zu lernen, gibt man sie probeweise in Wireshark ein (oben). In diesem Beispiel werden alle HTTP-Requests angezeigt, ausgenommen die über UPnP.
tshark-Ausgaben können je nach Verkehrsart und Filter kurz und übersichtlich sein. Oft werden das aber lange Listen, beispielsweise von angesteuerten Domains, und nicht selten kommen im Trace manche Domains immer wieder vor. Dann empfiehlt es sich, die tshark-Ausgabe mit einigen Unix-Befehlen zu sortieren. So erkennt man Zusammenhänge oder Häufigkeitsverteilungen.
Der Befehl
sortsortiert die Liste alphabetisch. Mehrfacheinträge stehen danach untereinander.
uniq -cfasst Mehrfacheinträge zusammen, also etwa Ziele, die das Smart-TV wiederholt angesprochen hat. Dabei stellt das -c für Count die Anzahl der Aufrufe an den Zeilenanfang. Jeder Eintrag belegt somit nur noch eine Zeile. Das danach folgende
sort /Rgibt die Liste abnehmend nach Häufigkeit aus, also als Rangliste.
Der gesamte Vorgang lässt sich leicht automatisieren, indem man die Befehle mittels Pipes (|) verkettet. Das sieht komplett unter Windows dann so aus:
Auf Linux und macOS setzt man anstatt des letzten Sort-Befehls
sort -g -r ein. Die Analyse eines von Philips gefertigten Smart-TV brachte hervor, dass das Gerät viele Webserver mittels HTTP-Requests kontaktiert. Neben Erwartbarem wie Netflix-Servern sind aber auch etliche unbekannte Ziele darunter, etwa zeasn.tv und smartclip.net – das Smart-TV ist offensichtlich ein Plappermäulchen.
HTTPS analysieren
Auch HTTPS-verschlüsselte Verbindungen lassen sich untersuchen. Das geht sogar mit vertretbarem Aufwand, denn beim HTTPS-Verkehr sind nur die Nutzdaten verschlüsselt, nicht aber die beim Verbindungsaufbau übertragenen Paket-Header.
Das ist nützlich, denn viele Server-Betreiber bieten über eine einzige IPv4-Adresse mehrere Domains an. Die gewünschte Domain steht im Header des HTTP-Requests im Feld „Server Name Indication“. Anhand dieser SNI liefert der Zielserver dem Browser das zur angefragten Domain passende TLS-Zertifikat und dann die angefragte Webseite aus. Außerdem nutzen auch Load-Balancer die SNI, um in komplexen Server-Umgebungen Anfragen vorzusortieren und weiterzuleiten.
Auch verschlüsselte HTTPS-Verbindungen liefern nützliche Meta-Daten, denn erst die auf den Header folgenden Nutzdaten sind chiffriert: Hier ist das HTTP-Header-Feld „Server Name Indication“ blau unterlegt, mit dem Browser mitteilen, welche Domain sie ansteuern wollen.
Um HTTPS-Server aus einem Trace zu isolieren, nehmen Sie als Display-Filter tls.handshake.extensions_server_name. Die Option fürs interessierende Feld lautet entsprechend
-T fields -e tls.handshake.extensions_server_name und der gesamte Windows-Befehl inklusive sort- und uniq-Pipe setzt sich so zusammen:
Heraus kommt eine ähnliche Liste wie bei der Filterung der unverschlüsselten Webserver. So kommt man den teils unerwünschten Verbindungen eines Smart-TV auf die Schliche.
Direkte DNS-Anfragen
Neben den HTTP(S)-Zielen gibt es weitere lohnenswerte Kandidaten für die Verkehrsanalyse, allen voran die Source- und Destination-IP-Adressen, also “ipv6.src” und “ipv6.dst” für das IPv6-Protokoll sowie “ip.src” und “ip.dst” für das veraltete IPv4. Aufschlussreicher sind aber schon DNS-Queries “dns.qry.name”, die unverschlüsselte Anfragen aller Clients sichtbar machen, unabhängig davon, ob ein Client später HTTPS-, SMTP- oder sonstige Verbindungen aufbaut.
So fiel in einem unserer Traces auf, dass das Smart-TV nicht nur den per DHCP im LAN konfigurierten DNS-Server befragt, sondern auch direkt mit Googles DNS-Resolver 8.8.8.8 plaudert. Das sollte nicht sein. Der Smart-TV-Hersteller ist aber vermutlich unschuldig: Anhand des Felds
dns.flags.response == 0 kann man davon ausgehen, dass die Google-Anfragen von der auf dem Smart-TV installierten Netflix-App kommen und nicht vom TV-Betriebssystem.
Wireshark beschleunigen
Eine der nützlichsten tshark-Anwendungen ist Datenreduktion, um die Analyse mit Wireshark zu beschleunigen. Wireshark kaut nämlich an großen Dateien lange herum, bis es etwas anzeigt, weil das Programm nach jeder Änderung des Display-Filters die komplette Datei neu einliest. Um alle aktuell ausgewählten Pakete einer 600 MByte großen Capture-Datei darzustellen, benötigt selbst ein moderner Rechner mit i7-Dualcore-Prozessor und 16 GByte RAM satte 40 Sekunden – bei jeder Änderung der Filterzeile.
Schon beim Mitschneiden einen reduzierenden Capture-Filter zu verwenden, ist aber kontraproduktiv: Bei Fehleranalysen wissen Sie zu Beginn oft nicht, wonach Sie suchen. Daher lautet die Regel: so viel mitschneiden, wie gerade vertretbar ist.
Um dennoch flüssig mit Wireshark arbeiten zu können, überlegen Sie zunächst, wo anzusetzen ist. Ein guter Startpunkt kann die DNS-Kommunikation sein. Extrahieren Sie also aus dem großen Mitschnitt alle DNS-Pakete in eine neue Datei mit dem Display-Filter
udp.port eq 53 or tcp.port eq 53. Der Ausdruck dns wäre zwar viel einfacher, aber er erfasst nur DNS-Verkehr. So würden Sie bei etwaigem TCP-DNS-Verkehr den Verbindungsaufbau verpassen.
Verwenden Sie nun tshark zum Einlesen der ursprünglichen Datei zusammen mit dem Filter, um eine verkleinerte Variante zu erzeugen:
Längere Mitschnitte segmentiert man geschickterweise, zum Beispiel in mehrere Dateien von je 100 MByte Größe. Denn wenn Sie den Verkehr von sehr schnellen Schnittstellen bei hohem Durchsatz mitschneiden, fallen in kürzester Zeit enorm große Dateien an. Mit tshark und etwas Know-how kann man dann Verdächtiges oder Wesentliches leicht extrahieren und Wireshark als Portiönchen zuführen.
Das erledigt, zusammen mit einer Filterung, einfacherweise ein Shell-Skript, im Beispiel unten als Windows-Batch-Datei. Sie legt die gefilterten Segmente in ein Unterverzeichnis und fasst sie dort mit dem ebenfalls zu Wireshark gehörenden Tool
mergecap zusammen:
for %a in (*.pcapng) do tshark -r %a -Y "udp.port eq 53 or tcp.port eq 53" -w subdir\%a
cd subdir
mergecap -w single-file.pcapng *.pcapng
Firmen-Admins nutzen tshark-Analysen auch zur Qualitätskontrolle: Wer beispielsweise einen öffentlichen autoritativen DNS-Server betreibt, kann die von Clients verwendeten DNS-Flags auslesen. So lassen sich Missetäter identifizieren, die fälschlicherweise rekursive DNS-Anfragen senden:
dns.flags.recdesired.
Qualitätskontrolle bei IPv6
Wenn Sie Server betreiben, die auf IPv6 antworten, bietet es sich an, ICMPv6-Fehlercodes zu analysieren. Die kommen von Backbone-Routern und Firewalls, wenn sie IPv6-Antwortpakete Ihres Servers nicht zustellen können. Mögliche Ursachen sind fehlende Routen, Routing-Loops oder auch blockierende Firewall-Policies. Um Fehler innerhalb Ihres eigenen Netzes auszuschließen, hilft der Blick auf die Details. Dabei sind folgende zwei Felder relevant:
-e icmpv6.type -e icmpv6.code.
Wenn darin der Fehler „Typ 1 Code 0“ steckt, bedeutet das „no route to destination“. Router senden ihn, wenn sie ein Paket mangels korrekter Route nicht zustellen können. Wenn Ihr Server diesen Fehler beim Versuch erhält, auf eine Anfrage aus dem Internet zu antworten, ist die Source-IPv6-Adresse vielleicht gefälscht oder das Routing des entfernten Netzes vermurkst.
„Typ 1 Code 3“ beziehungsweise „address unreachable“ bedeutet, dass der letzte Router des Übertragungspfads die Ziel-IPv6-Adresse (Layer 3) nicht zur MAC-Adresse (Layer 2) auflösen konnte. Das kann an fehlkonfigurierten IPv6-Stacks von Clients oder versehentlichem Blocken der IPv6-Neighbor-Solicitations liegen – diese sind für die Auflösung erforderlich. In beiden Fällen kann der Client nicht per IPv6 kommunizieren – verwunderlich, dass es noch keinem auffiel.
„Typ 3 Code 0“ beziehungsweise „hop limit exceeded in transit“ ist der Klassiker unter den ICMPv6-Fehlern. Er deutet auf einen Routing-Loop hin: Zwei Router referenzieren sich gegenseitig, womöglich gehören sie zu Ihrem Netzwerk. Ob das der Fall ist, finden Sie mit dem Befehl
traceroute heraus.
Dass solche Fehler alltäglich sind, demonstriert eine Liste von vier Servern des NTP-Pools. Binnen 24 Stunden liefen Tausende von ICMPv6-Fehlermeldungen auf, die mit dem folgenden Skript extrahiert wurden:
Erstaunlicherweise traten gleich sieben Fehlertypen auf. Da liegt noch einiges im Argen bei der IPv6-Implementierung mancher Netzbetreiber.
Security-Analysen mit tshark
Die Datenaufbereitung mit tshark hilft auch bei der Analyse von Security-Problemen. So hat der Autor damit untersucht, ob Load-Balancer von F5 Networks gegen die Logjam-Attacke anfällig sind. Logjam nutzt aus, dass ältere TLS-Implementierungen bei der Diffie-Hellman-Schlüsselvereinbarung öffentliche Schlüssel (Public Keys) nicht nur einmal, sondern mehrfach verwenden. Das können Angreifer nicht nur nutzen, um verschlüsselte Inhalte mitzulesen, sondern auch um sie zu verfälschen.
Veraltete TLS-Implementierung: Manche Geräte nutzen beim Schlüsselaustausch gemäß Diffie-Hellman einen Public Key mehr als nur einmal. Angreifer können das nutzen, um verschlüsselte Daten mitzulesen und zu modifizieren.
Startpunkt für die Analysen ist Wireshark. Im Mitschnitt suchen Sie zunächst ein Paket mit dem Handshake-Type „Server Key Exchange“. Im Bildbeispiel ist dieses Element mit (1) markiert. Den Ausdruck als Display-Filter eingesetzt (2), zeigt Wireshark die Pakete mit diesem Inhalt an. Der Bezeichner dieses Felds (3) erscheint nach einem Klick unten (4). Praktisch: Per Rechtsklick und „Apply as Column“ blendet Wireshark dieses Feld als zusätzliche Spalte in der Paketübersicht ein (5). Schon offenbart sich, dass die ersten vier Einträge – also Public Keys – identisch sind.
Damit ist das Problem bewiesen und man braucht tshark eigentlich nicht mehr, aber Trace-Files lassen sich nicht immer in Wireshark öffnen. Manche liegen auf entfernten Rechnern und wenn sie groß sind, lohnt die Übertragung für solche Analysen kaum. Also nutzt man tshark über ssh direkt auf dem fernen Rechner: Public Keys identifizieren Sie über die Optionen
-Y tls.handshake.type == 12 sowie
-T fields -e tls.handshake.ys und sortieren die Ausgabe wieder mit
sort | uniq -c | sort /R.
Letztlich hängt es stark von der Anwendung ab, welche Paketfelder man isolieren will. tshark bietet Ihnen genau diese Möglichkeit und bewahrt Sie davor, im Morast einer riesigen Trace-Datei zu versinken. Mit wenigen Handgriffen untersuchen Sie das Surfverhalten Ihres Sprösslings oder Ihrer IoT-Geräte selbst – mausschonend und ohne Copy-&-Paste, Zettelwirtschaft oder Excel.
Netzwerkverkehr mitschneiden: So gehtsDie verbreiteten Fritzboxen und manche Speedport-Router können direkt Paketmitschnitte anfertigen.
Der Netzwerkverkehr lässt sich je nach Gerät auf unterschiedliche Weise aufzeichnen: Auf dem lokalen PC nimmt man klassisch Wireshark. Das bietet Wireshark direkt nach dem Programmstart an; man muss lediglich die Netzwerkschnittstelle auswählen und den Start-Button klicken.
Den Verkehr von Geräten, auf denen Wireshark nicht läuft, kann die Mitschnitt-Funktion des Routers liefern. Auf den verbreiteten Fritzboxen findet man sie unter der Adresse http://fritz.box/html/capture.html, auf manchen Speedport-Routern unter http://www.speedport.ip/html/capture.html.
Im Firmen-Umfeld gehört Packet-Capturing bei modernen Firewalls wie denen von Palo Alto Networks oder Fortinet zum Pflichtenheft, man startet es über deren Konfigurationsseiten. Um den Durchsatz nicht in die Knie zu zwingen, sollten Sie den Mitschnitt auf die IPv4- und IPv6-Adressen des interessierenden Clients beschränken.
An Firmen-Switchen mit Port-Mirroring, auch SPAN-Port (Switched Port-Analyzer), können Sie den Verkehr ausleiten. Wenn man den Client-Port vorübergehend auf 100 MBit/s drosselt, reicht die Kapazität des Mirror-Ports (1 GBit/s) sicher für beide Richtungen. Aber mit der langsamen Datenrate kann der Fehler verschwinden.
Admins mit größerem Budget greifen deshalb zu einem professionellen Terminal Access-Point (TAP) mitsamt Capture-Card. Erst der schreibt sämtliche Pakete jederzeit korrekt mit und liefert so genaue und zuverlässige Traces.
Unabhängig vom Aufzeichnungsgerät werden die Mitschnittdateien üblicherweise in den Formaten PCAP oder PCAPNG gespeichert, die Wireshark, tshark und Konsorten verstehen.
Wenn es im Netzwerk knirscht, versuchen Admins den Fehler in Analyse-Tools wie Wireshark anhand von Paketmitschnitten einzukreisen. Jedoch hat der Herr viel mehr Netzwerkprotokolle gegeben, als sich ein Admin-Hirn in allen Details merken kann. Eine Referenzdatei, die zahlreiche korrekte Protokollabläufe enthält, gibt Orientierung.
Diesen Artikel habe ich initial für die c’t geschrieben, wo er im Heft 24/2020 erschienen ist. Als Autor habe ich dankenswerterweise die Erlaubnis, ihn hier auf meinem Blog ebenso zu veröffentlichen. Eine Übersicht der von mir geschriebenen c’t Artikel gibt es hier.
Wer den Netzwerkverkehr auf Kommunikationsfehler abklopfen muss, braucht bei der Analyse von Paketmitschnitten (Traces) reichlich Geduld. Abgelaufene Zertifikate, Inkompatibilitäten aufgrund verschiedener Versionen, fehlerhafte Implementierungen, abgelaufene Timer – der Fehler steckt oft im Detail.
Natürlich kann man einen Trace im Analysewerkzeug Wireshark öffnen und die Aufzeichnung Paket für Paket und Feld für Feld mit den Spezifikationen vergleichen. Ein Fehler springt aber eher ins Auge, wenn man einen funktionierenden Protokollablauf zum Vergleich heranzieht.
Manche Netzwerk-Admins sammeln daher Traces funktionierender Übertragungen, um sie später als Referenz zu verwenden. Auch der Autor dieses Beitrags hat wichtige Traces über Jahre hinweg gesammelt. Anstatt aber vor jeder Analyse die zugehörige Referenzdatei im händisch angelegten Archiv zu suchen, hat er die wichtigen Mitschnitte in ein einziges PCAP-File gesteckt. Das kann man wie üblich mit einem Doppelklick in Wireshark öffnen und dann die mächtige Filtermaschine des Programms nutzen, um einen gesuchten Protokollablauf darzustellen.
In diesem Beitrag geht es um eine rund 9 MByte große Referenzdatei. Sie enthält aktuell über 60 Traces von Protokollen, die auf das Übertragungsmedium Ethernet aufsetzen; Sie finden sie über ct.de/yjkz.
Die meisten Beispiele sind sowohl für das moderne IPv6 als auch für das veraltete IPv4 ausgeführt. Unter anderem befinden sich in der Referenzdatei sowohl Abläufe grundlegender Protokolle wie DNS, HTTP oder ICMP als auch von Exoten wie Ciscos Unidirectional Link Detection (UDLD) oder vom langsam aussterbenden WHOIS. Die komplette Liste haben wir in einer Tabelle aufgeführt, die ebenfalls unter ct.de/yjkz zum Download bereitsteht.
In Wireshark kann man mit flexiblen Display-Filtern allen Verkehr ausblenden, der gerade nicht interessiert, und so ausschließlich die zu analysierende Kommunikation verfolgen. Bei vielen Protokollen hat man die Wahl zwischen zwei Filterarten: Setzt man zum Beispiel
http oder
dns ins Feld „Display-Filter“ ein, dann zeigt Wireshark nur die Pakete, die zum jeweiligen Applikationsprotokoll gehören.
Wenn man stattdessen auf den Zielport filtert, zeigt Wireshark zusätzlich den Transport Layer Overhead, der beim Verbindungsaufbau abläuft, inklusive Acknowledgements und etwaiger Retransmissions. Um also eine komplette Websession zu betrachten, gibt man
tcp.port eq 80 ein.
Überblick
Die Kommunikation von Hosts mit dem Domain Name System (DNS) gehört zu den grundlegenden Anwendungen. Praktisch jedes internetfähige Programm benötigt zur Verbindungsaufnahme die Auflösung von Domainnamen zu A- oder AAAA-Records mit ihren IP-Adressen, sodass solche Pakete in fast jedem Trace zu finden sind. Der Großteil der weltweiten DNS-Anfragen an die DNS-Resolver läuft unverschlüsselt ab, was auch die Referenzdatei widerspiegelt; verschlüsselnde Protokolle wie DNS-over-HTTPS und DNS-over-TLS fassen aber langsam Fuß und werden daher in einem kommenden Update der Referenzdatei berücksichtigt.
Um den DNS-Verkehr isoliert zu betrachten, gibt man im Display-Filter
dns ein. Mit dem Filter
tcp.port eq 53 or udp.port eq 53 sehen Sie die gesamte Kommunikation zur Namensauflösung, also auch etwaigen TCP-Overhead.
DNS-Probleme können vielfältig sein. Daher sind in der Referenzdatei allerlei DNS-Beispiele aufgeführt, angefangen von Paketen, die seltene Resource Records (RR) enthalten, bis hin zu kompletten Zone Transfers.
Außerdem finden Sie darin Besonderheiten wie Hostnamen, die Sonderzeichen enthalten (internationalized domain names, IDN), und Anfragen zu A- oder AAAA-Records mit bis zu 64 IPv4- oder IPv6-Adressen pro Host. Nicht zu vergessen DNSKEYs und RRSIGs der kryptografischen DNS-Absicherung DNSSEC sowie die zugehörigen Flags in den Antworten. Für Domain-Admins interessant: Dynamische DNS-Updates (nicht zu verwechseln mit DynDNS eines Heimrouters).
Bei genauem Hinsehen fallen neben klassischen UDP-Paketen auch IP-Fragmente sowie TCP-Sessions auf. Diese treten immer dann auf, wenn eine DNS-Antwort nicht mehr in ein UDP-Paket passt. Herkömmliche DNS-Antworten dürfen nicht länger als 512 Bytes sein, um mittels UDP übertragen werden zu können. Mit der Erweiterung EDNS(0) signalisiert ein Server, dass er mehr Nutzdaten verschickt (> 512 <= 1232 Bytes). Sollte die EDNS(0)-Übertragung scheitern oder die Obergrenze überschreiten, kann der Client den Server über das aufwendigere und langsamere TCP befragen.
DNS-Anfragen laufen nicht nur über den UDP-Port 53 ab: Bei dieser DNSSEC-Validierung ist die Antwort auf die Frage (1) nach dem DNSKEY zu groß für ein UDP-Datagramm und daher sendet der Resolver: „Message is truncated“ (2). Die DNS-Response enthält also keine Nutzdaten (3). Der DNS-Client fragt daher noch einmal per TCP nach (4).
Was wäre das Internet ohne HTTP? Klar, dass das Trace-File auch ein paar HTTP-Sessions enthält. Kleiner Wireshark-Tipp: Klicken Sie mit der rechten Maustaste auf ein HTTP-Paket und dann im Kontextmenü auf „Follow/HTTP Stream“. Daraufhin öffnet sich ein Fenster, das nur den Inhalt des HTTP-Headers und des Bodys anzeigt; etwaige komprimierte Inhalte werden automatisch dekomprimiert.
Wer HTTP-Verkehr im Unternehmensumfeld analysiert, muss mit Proxys rechnen. Eine häufige Frage ist daher: Wie kann man, abgesehen von der IP-Adresse des Proxys, auf reinen HTTP- oder Proxy-vermittelten Verkehr rückschließen? Ein Beispiel dafür liefert der Host mit der IP-Adresse 192.168.110.10 (Display-Filter
ip.addr == 192.168.110.10). Dieser hat eine Webseite sowohl direkt als auch per Proxy aufgerufen. Wenn er nur
GET / sendet, kommuniziert er mit dem Webserver direkt. Schickt er hingegen
GET http://<hostname>/, nutzt er den Proxy.
Doch der Webverkehr hat sich schon seit einiger Zeit überwiegend zu TLS-verschlüsseltem HTTP verlagert, also HTTPS. Im Trace sind mehrere TLS-1.2- und -1.3-Sessions zu sehen.
Möchten Sie wissen, welche Hostnamen ein Client aufgerufen hat? Schauen Sie sich den DNS Query, den HTTP Host oder die Server Name Indication (SNI) an, hier zusammengefasst in nur einer Spalte (2).
Dabei ist zwar der Großteil der Kommunikation verschlüsselt, aber immerhin kann man leicht erkennen, welche Hostnamen ein Client aufruft (Server Name Indication, SNI). Mit dem Filter
tls.handshake.extensions_server_name lassen sich alle Pakete isolieren, die ein SNI-Feld enthalten (siehe Screenshot oben). Sie möchten wissen, welche Server-Zertifikate im Trace stecken? Setzen Sie im Display-Filter
tls.handshake.type == 11 ein.
Die Referenzdatei eignet sich auch zum Testen von Display-Filtern (1). Im obigen Screenshot sind gleich mehrere Beispiele für den Einsatz von logischen Operatoren wie and und or sowie Klammern mit mehreren Werten aufgeführt
in { x y z }. Sie lassen sich auch in selbsterstellten Spalten, den „Custom Columns“ verwenden.
Die Spalte unter (2) wird per
dns.qry.name or http.host or tls.handshake.extensions_server_name erzeugt. So führt eine einzige Spalte die DNS-Pakete der angefragten Namen auf, dazu den per HTTP-Session angesprochenen Host und bei HTTPS-Verbindungen auch die Server Name Extension – sehr praktisch für einen schnellen Überblick über das Surfverhalten.
Zum Schluss sei unter den grundlegenden Protokollen das Internet Control Message Protocol (ICMP) genannt, es kommt beim täglich millionenfach genutzten Ping zum Einsatz. Damit versendet man Pakete vom Typ “echo-request” und erhält vom angepingten Host Antworten vom Typ “echo-reply”. Übliche Ping-Befehle zeigen nicht wirklich Überraschendes, aber durchaus der Traceroute-Befehl, der ICMP in Kombination mit inkrementierten Hop-Limits verwendet (bei IPv4 „TTL“), um Routern auf der Strecke zu einem Ziel Lebenszeichen zu entlocken.
Während der Windows-Befehl
tracert die engen ICMP-Rahmenbedingungen weitgehend umsetzt, lassen sich mit den
traceroute-Implementierungen von Unix-Betriebssystemen sogar beliebige TCP- oder UDP-Ports ansprechen und auch Netzwerkpfade hinter Firewalls identifizieren. In der Referenzdatei steckt ein solches Beispiel für den SMTP-Port TCP-25. Finden Sie es? Tipp: Die betreffende Traceroute-Session lief auf IPv6.
Routing-Protokolle
Das Rückgrat großer Netzwerke und des Internets bilden Routing-Protokolle, mit denen sich Backbone-Router gegenseitig ins Bild setzen, über welche Strecken sie bestimmte andere Netzwerke erreichen. In internen Netzen sind das Routing Information Protocol (RIP) beziehungsweise das Routing Information Protocol next generation für IPv6 (RIPng) gebräuchlich. Damit meldet jeder Router alle ihm bekannten Netzwerke periodisch an eine Multicast-Adresse und teilt sie so allen anderen Routern im privaten Netz mit.
Für komplexere Netze hat sich Open Shortest Path First (OSPF) durchgesetzt. Alle beteiligten Router senden periodisch ein Hello-Paket; Informationen über Router und angeschlossene Layer-3-Netze fließen nur bei Änderungen. Mit seinen zig verschiedenen Link State Advertisements (LSA) zählt das Protokoll zu den komplexen. Wie gut, dass Sie im PCAP diverse solcher LSA-Typen finden und erforschen können.
OSPF ist ein selbstständiges Protokoll, das wie TCP auf der IP-Schicht aufsetzt. Die Protokollnummer lautet 89 (1). In der obigen Abbildung ist auch der Authentication Header (AH) der Protokollnummer 51 (2) zu sehen, denn beim betreffenden Paket handelt es sich um OSPFv3 für IPv6 mit eingebauter Authentifizierung. Der Großteil des Pakets besteht aus Netzwerkinformationen im Klartext (3).
Internet-Router kommunizieren miteinander über das Border Gateway Protocol (BGP), das den TCP-Port 179 nutzt und manuell zwischen zwei Routern eingerichtet wird (BGP-Nachbarschaft, engl. Neighbors). Anschließend können sie Informationen über erreichbare IPv4- und IPv6-Netze austauschen. Ob eine BGP-Session über IPv4 oder IPv6 aufgebaut wurde, spielt keine Rolle.
Zur gegenseitigen Authentifizierung haben sich einfache BGP-Passwörter in Form von Pre-Shared Keys etabliert; damit wird eine MD5-Prüfsumme über jedes BGP-Päckchen gebildet. Wer diese Prüfsumme am Ende des BGP-Pakets vermutet, wird jedoch nicht fündig, denn sie wird als TCP-Option übertragen und steckt daher vorn im TCP-Header.
Um in der Referenzdatei ausschließlich BGP-Nachrichten darzustellen, genügt es,
bgp als Display-Filter zu verwenden. Möchten Sie den kompletten TCP-Overhead sehen, verwenden Sie
tcp.port eq 179.
IPv6-Crashkurs
Der Internet-Verkehr wird verschiedenen Statistiken zufolge mittlerweile zu mehr als 30 Prozent über IPv6 abgewickelt, für Deutschland meldete Google Ende Oktober 2020 schon 50 Prozent IPv6-Anteil (siehe ct.de/yjkz). In Firmenumgebungen ist der Anteil weit geringer, denn viele Unternehmen betreiben ihre Infrastruktur noch weitgehend nur mit IPv4. Moderne Betriebssysteme nutzen IPv6 aber zumindest im LAN (Layer 2, Link-lokal), sodass IPv6-Pakete auch in vermeintlich reinen IPv4-Umgebungen übertragen werden. Manch ein Admin argwöhnt dann ein Fehlverhalten im Netz.
Die Referenzdatei kann auch hier Licht ins Dunkel bringen. Anwendungsprotokolle wie DNS, HTTPS oder SSH nehmen mit beiden IP-Protokollen vorlieb, bevorzugen aber IPv6. Um sich zu vergewissern, kann man beispielsweise nach
ipv6 and http filtern und so etwa hausinterne IPv6-Kommunikation mit Druckern sehen (z. B. AirPrint), die sich Link-lokale IPv6-Adressen per Autokonfiguration erwürfelt haben.
Wer sich eingehend mit IPv6 beschäftigt, wird schnell auf eine Fülle von ICMPv6-Nachrichten stoßen. Diesem Thema widmet sich die Referenzdatei ganz am Anfang: Setzen Sie im Display Filter
ipv6 ein. Die daraufhin eingeblendeten Kommunikationsabläufe kann man als kleinen IPv6-Crashkurs nutzen. Es geht los mit Paketnummer 32.
Zunächst ist der Ablauf der automatischen Adressvergabe per Stateless Address Autoconfiguration zu sehen (SLAAC). Ein frisch gebootetes Knoppix-Linux versorgt sich mit zwei IPv6-Adressen: einer Link-lokalen, die mit
fe80:: beginnt und nur im lokalen Netz gilt, sowie einer Global Unicast Adresse (GUA), die weltweit gilt und eindeutig ist. Der Linux-Rechner ist über einen Speedport-Router an einem Telekom-Anschluss mit Dual-Stack-Konfiguration angeschlossen, kann darüber also sowohl per IPv4 als auch per IPv6 mit Internet-Hosts kommunizieren. Den Adressbereich (IPv6-Präfix) für seine GUA erhält er über den Router vom Provider, also von der Telekom.
Dabei laufen folgende Schritte ab:
Der PC sucht mittels Router Solicitation nach einem Router im LAN (Paket 39). Der Router schickt ein Router Advertisement (Paket 43) mit dem vom Provider zugewiesenen /64-Präfix. Der zugehörige Display-Filter lautet
icmpv6.type in { 133 134 }.
Der Client erzeugt unter Verwendung seiner MAC-Adresse zwei IPv6-Adressen für sich selbst, die Link-lokale und die globale Adresse, abgeleitet aus dem Präfix. Bevor er sie nutzt, fragt er per Duplicate Address Detection (DAD) im Netzwerk nach, ob sie in Verwendung sind. Technisch gesehen handelt es sich um eine Neighbor Solicitation, gesendet von der Null-Adresse (unspecified) “::”. Der Display-Filter lautet:
icmpv6.type eq 135 && ipv6.src eq ::.
Nun fehlt dem Client noch ein DNS-Server (Resolver) zur Namensauflösung. Solche IP-Adressen kann ein Client wahlweise per Router Advertisement beziehen (z. B. Paket 21190) oder per DHCPv6 (z. B. Pakete 44 und 45). Aber Achtung: Es handelt sich um „stateless DHCPv6“, also nur um die Bekanntmachung des Resolvers, nicht um die Vergabe von IPv6-Adressen.
Die Link-Layer Address Resolution ist das IPv6-Gegenstück zum Address Resolution Protocol von IPv4 (ARP): Ein Endgerät möchte zu einer IP-Adresse die zugehörige MAC-Adresse auf der Ethernet-Schicht herausfinden. In der IPv6-Spezifikation gehört diese Funktion zu ICMPv6 und heißt Neighbor Discovery. Ein anfragender Client hängt die letzten 24 Bit der gesuchten Unicast- oder Anycast-Adresse an das Multicast-IPv6-Präfix ff02::1:ff00:0/104 an und schickt sie als Neighbor Solicitation ab. Die gesuchte Gegenstelle antwortet mit einem Neighbor Advertisement. Filter:
icmpv6.type in { 135 136 }.
Die Multicast Listener Discovery (MLD) sollte eigentlich das IPv6-Gegenstück zum Internet Group Management Protocol (IGMP) auf IPv4 sein. Filter:
icmpv6.type in { 130 131 132 143 }. Es gibt aber kaum Layer-2-Switche, die so etwas wie „MLD-Snooping“ verwenden. Das ist unüblich, weil fehleranfällig. Daher sind MLD-Pakete in der Praxis bedeutungslos und man kann sie ignorieren.
Spätestens jetzt ist klar: ICMPv6-Pakete können sehr unterschiedliche Funktion haben. Etwas unkomfortabel erscheint daher, dass Wireshark in der Grundkonfiguration alle ICMPv6-Pakete gleich einfärbt (siehe linkes Fenster im Screenshot oben).
Die Wireshark-Färberei kann man aber auch konfigurieren. Das zugehörige Fenster mit diversen manuellen Regeln ist im obigen Screenshot auf der rechten Seite zu finden. In der Mitte des Screenshots sehen Sie das Einfärbeergebnis dieser Regeln: MLD-Pakete sind absichtlich kaum sichtbar (hellgrüne Schrift auf weißem Grund), Duplicate Address Detection ist grün unterlegt, Router Solicitation/Advertisement lila und die Neighbor Discovery türkis. Übliche Pings (Pakete 83 und 86) sind unauffällig pink.
Hai-Färberei: Wer die Funktion der unterschiedlichen ICMPv6-Pakete optisch herausheben will, kann in Wireshark die Coloring Rules nach eigenem Gusto anpassen. Links sind ICMPv6-Pakete gemäß einer üblichen Wireshark-Regel eingefärbt, rechts mit angepassten Regeln.
Unverschlüsselt
Früher oder später kann es jeden Netzwerkadmin treffen: das Entsetzen darüber, dass eigene Netzwerkgeräte ungewollt unverschlüsselt kommunizieren. Beispielsweise treiben manche FTP-Clients auf PCs ihr Unwesen. Obwohl Serverbetreiber im Internet, beispielsweise für Webauftritte, die Wartungszugänge längst per TLS abgesichert haben, kommt es bei falschen Client-Einstellungen trotzdem zu Plaintext-Übertragungen – inklusive des Passworts. Autsch.
Wohl dem, der beispielsweise FileZilla einsetzt. Wenn möglich, nutzt das Programm FTP über TLS. Aber mancherorts sind noch veraltete FTP-Programme im Einsatz und auch der Windows Explorer von Windows 7 verschlüsselt seine FTP-Kommunikation nicht. Wie das aussieht, finden Sie mit dem Display Filter
ftp or ftp-data heraus.
Auch SMTP und IMAP können TLS-abgesichert kommunizieren, aber ist das bei Ihren Servern der Fall? Manche Admins wähnen ihr Netz hinter der NAT ihres Routers in Sicherheit und betreiben interne SMTP- und IMAP-Server aus Bequemlichkeit unverschlüsselt – ein gefundenes Fressen für Emotet und andere Botnetze.
Bei den heute üblichen VoIP-Telefonaten ist die Lage vertrackt: Unter anderem kann man zwar SIP over TLS und sRTP zum Verschlüsseln von Steuer- und Nutzdaten verwenden, aber in Deutschland sind sie wenig verbreitet. Derzeit kann man nur VoIP-Konten der Telekom, EasyBell und Dus.net mit diesen beiden Protokollen absichern. Einige Router eignen sich bereits dafür, darunter Fritzboxen ab FritzOS 7.20 (siehe ct.de/yjkz).
Viele VoIP-Anbieter setzen die unverschlüsselten Protokolle SIP und RTP ein. Wenn Sie sich überzeugen wollen, wie einfach es ist, VoIP-Telefonate mitzuhören: Klicken Sie in Wireshark auf „Telephony/VoIP Calls“, wählen Sie einen der drei erkannten Anrufe aus und klicken Sie anschließend auf „Play Streams“.
Ausblick
„Ich weiß, dass ich nichts weiß“: Auch wenn diese Referenzdatei zahlreiche Protokolle enthält, kann sie nicht die Anforderungen aller Admins der Welt erfüllen. Sie lässt sich aber erweitern. In späteren Updates könnten die für Datacenter relevanten Protokolle MPLS, VXLAN oder ERSPAN hinzukommen, auch Klassiker wie POP3, LDAP oder NFS. Neuentwicklungen wie QUIC oder DNS-over-TLS sind ebenfalls spannende Kandidaten.
Dennoch sind die Anwendungsbereiche schon jetzt vielfältig: Man kann die Datei zum Vergleich mit einem lokalen Fehlerbild nutzen, zum Experimentieren mit Wireshark-Filtern, zum Testen von Netzwerk-Tools oder für Schulungszwecke. Möge sie auch Ihnen weiterhelfen.
Das moderne Internetprotokoll IPv6 gilt als so komplex und umständlich, dass manche Administratoren beharrlich beim vertrauten, aber veralteten IPv4 bleiben. Zehn Praxisbeispiele belegen, warum viele Netzwerkanwendungen besser und kostengünstiger auf IPv6 laufen und wie Admins davon profitieren.
Diesen Artikel habe ich initial für die c’t geschrieben, wo er im Heft 07/2022 erschienen ist. Als Autor habe ich dankenswerterweise die Erlaubnis, ihn hier auf meinem Blog ebenso zu veröffentlichen. Eine Übersicht der von mir geschriebenen c’t Artikel gibt es hier.
Profi-Admins und viele Netzwerk-Interessierte wissen längst, weshalb IPv4 unzulänglich ist: Dessen Adressraum ist gemessen am weltweiten Bedarf viel zu klein und Netzwerke auf IPv4-Basis laufen nur mit der Krücke Network Address Translation (NAT) weiter – diese bildet teils riesige Netze mit privaten IPv4-Adressen auf wenige oder gar nur eine öffentliche IPv4-Adresse ab. Weiter unten finden Sie mehr Beispiele für Netzwerkprobleme, die allein der IPv4-NAT geschuldet sind.
Aber jeder Admin weiß auch: IPv6 gewinnt zwar weltweit an Zulauf, doch kaum eine Firma wird mit IPv6 auch nur einen Cent mehr einnehmen; es gibt ja keine Geschäftsmodelle, die exklusiv auf IPv6 gründen. Warum also sollte man den Aufwand auf sich nehmen und etablierte IPv4-Methoden und -Werkzeuge einmotten?
Die Antwort zeigt sich auf dem Überstundenzettel des Admins: IPv4 verursacht bei vielen gängigen Anwendungen einen so großen Konzeptions- und Pflegeaufwand, dass sich eine Umstellung auf IPv6 mittelfristig bezahlt macht, weil sich die Netzwerkerweiterung und -pflege spürbar vereinfacht. Auch lassen sich manche Probleme, die IPv4 stellt, nur mit IPv6 lösen. Wenn Sie erst mal IPv6 eingeführt haben, können Sie Adressbrokern eine lange Nase drehen. Denn deren Geschäftsmodell setzt darauf, sich von IPv6-scheuen Unternehmen ihren kleinen Rest noch freier IPv4-Adressen vergolden zu lassen.
Heimnetz-Admins haben hingegen andere Sorgen mit der Umstellung von IPv4 auf IPv6. Unter anderem fehlt den verbreiteten Fritzbox-Routern eine IPv6-Implementierung der VPN-Technik. Da bessert der Hersteller aber nach.
Aller Anfang ist auch für den Firmen-Admin schwer und die erste Hürde stellt sich schon mit der Länge der IPv6-Adressen. “Die sind mir viel zu lang, die kann ich mir nicht merken.” Diesen Satz dürfte jeder Netzwerker oder IT-Admin schon mal gehört haben.
Natürlich sind IPv6-Adressen weit länger als IPv4-Adressen. IPv4-Adressen bestehen aus 4 Byte, die zu vier Blöcken mit Werten von 0 bis 255 unterteilt sind (32 Bit). IPv6-Adressen bestehen aus 16 Byte, die zu je acht Blöcken aus vier Hexadezimalstellen von 0 bis F unterteilt sind (128 Bit).
Doch gerade die Länge ist ein Gewinn, denn damit lassen sich die Adressen besser strukturieren. Das bringt in der Praxis vor allem bei komplexen Netzen in Unternehmen und Institutionen eine Fülle von Vorteilen. Man erkennt nur nicht alle auf den ersten Blick.
Vorteil 1: Zu merkende Präfixe
Viele mittelständische bis große Unternehmen haben im Laufe der Jahre mehrere öffentliche IPv4-Adressbereiche in Betrieb genommen. Zusätzlich verwendet jede Firma im internen Netz mindestens einen der üblichen privaten IPv4-Adressblöcke (10.0.0.0/8, 172.16.0.0/12 und 192.168.0.0/16). Das kann erforderlich sein, um Filialen zu koppeln oder das Netz in Subnetze aufzuteilen, sodass zum Beispiel Versand, Buchhaltung, Forschung, Produktion, Geschäftsleitung und Administration in verschiedene Security-Zonen aufgeteilt sind.
Bildet der Admin solche Strukturen mit IPv4 ab, hantiert er zwangsläufig mit den verschiedenen Präfixen der drei privaten Adressblöcke. Da sie aus obigen Gründen oft noch weiter unterteilt sind, kommt man leicht auf 3 bis 6 Blöcke, mit denen man im Alltag jonglieren muss.
Nicht so bei IPv6: Geschäftskunden erhalten in der Regel einen festen /48-Block und große Netzwerke bekommen leicht auch einen /32-Bereich. In beiden Fällen beträgt die Anzahl der zu merkenden Präfixe: eins! Und das Präfix ist schnell gelernt, weil es ja nur die ersten zwei Hextets umfasst, beispielsweise 2001:db8::/32.
Je nach Größe des Adressblocks schließt sich dann für die Subnetze der Adressraum des dritten oder vierten Hexadezimalblocks an (z. B. 16 Bit). In der Abbildung “IPv4 vs IPv6 Adressvorteile” (oben) wird dieser Unterschied offensichtlich: Bei IPv4 muss man die privaten und öffentlichen Allokationen vor Augen haben, während es mit IPv6 nur eine Zuweisung ist.
Vorteil 2 und 3: Site-to-Site-VPN
Viele Firmengruppen und Unternehmen unterhalten untereinander VPN-Verbindungen (Site-to-Site). Aufgrund des knappen IPv4-Adressraums sind bei allen Firmen private IPv4-Adressen unverzichtbar. Da es aber nur drei unterschiedliche Adressräume für private Netze gibt, ist die Wahrscheinlichkeit hoch, dass zwei Firmen intern denselben Bereich verwenden, beispielsweise 192.168.1.0/24. Dann sind Adresskollisionen und damit Admin-Kopfschmerzen unausweichlich.
Aus diesem Dilemma führen verschiedene Wege: Eine der beiden Firmen könnte ihr Subnetz in einen anderen Bereich verlegen. Doch der Aufwand ist viel zu hoch, fehlerträchtig und je nach verwendeten Diensten vielleicht gar nicht im laufenden Betrieb möglich – es ist jedenfalls für jeden Admin, der mehr als 20, 30 Netzwerkgeräte betreut, eine haarsträubende Vorstellung. Und wenn beide Firmen alle drei privaten IPv4-Adressblöcke nutzen, funktioniert der Weg gar nicht (10/8, 192.168/16 und 172.16/12).
Stattdessen konfiguriert man separate Adressen, die im jeweils anderen Netzwerk nicht vorkommen und richtet sie im VPN-Router mittels internen NATs als Vermittler ein – so sind Adresskollisionen ausgeschlossen, aber auf Kosten der Übersicht. Die Pflege und Fehlersuche ist in solchen Netzen deutlich aufwendiger.
Oft sind sogar ein Source- und ein Destination-NAT erforderlich, damit nicht nur die Hin-, sondern auch die Rück-Route klappt, ohne zu große Netzbereiche auf einer der Seiten belegen zu müssen.
Als Beispiel: Firma A teilt ihren internen Geräten IP-Adressen aus den Bereichen 192.168.0.0/24 und 192.168.10.0/24 zu. Die Partnerfirma B, zu der A ein VPN aufsetzen will, verwendet diese beiden Bereiche ebenso.
Der Client mit der IP-Adresse 192.168.0.5 möchte auf Server 192.168.10.10 von Firma B zugreifen. Da Firma A diesen Adressbereich aber bereits anderweitig verwendet, richtet man ein statisches Destination-NAT aus einem reservierten Block als Vermittler ein: 192.168.110.10 vermittelt dann den eingehenden VPN-Verkehr zum Server von Firma B. Diese kann die IP-Adresse des Firma-A-Clients nicht zurückrouten, weil diese bereits bei Firma B anderweitig in Einsatz ist; sie verwendet intern ebenfalls den Adressbereich 192.168.0.0/24. Also behilft sich Firma B mit einem Source-NAT. Somit sind für eine Client-Server-Verbindung vier Subnetze im Spiel.
Es leuchtet unmittelbar ein, dass solche Umwege aufwendig zu konfigurieren und der Übersicht abträglich sind. Das Troubleshooting von Client-Server-Verbindungen wird schnell zum Albtraum, denn in den Logs stehen auf beiden Seiten diverse IPv4-Adressen, die der Admin gedanklich korrekt zuordnen muss (und besser gleich auf einer Skizze notiert), obwohl für das VPN nur eine IP-Session im Spiel ist.
Mit jedem weiteren Site-to-Site-VPN potenziert sich der Aufwand, weil weitere NAT-Regeln hinzukommen; der IPv4-Adressdschungel wird immer undurchdringlicher. Dann muss man schon zum Aufsetzen der NATs mehr Probleme lösen als zur Konfiguration des VPN. Dabei sind zwei NAT-Regeln nur ein Beispiel. Je nach Infrastruktur können für eine einzige Site-to-Site-Verbindung mehr NATs erforderlich sein. Und Admins, die VPN-Verbindungen zu mehreren Partnern mit identischen IPv4-Subnetzen aufbauen wollen, können gleich auch Haarfärbemittel bestellen.
Der Umstieg auf IPv6 ist sicher auch aufwendig – aber einen Tod muss man sterben. Und wenn man sich einmal für IPv6 entschieden hat, wird Site-to-Site-VPN plötzlich zum Kinderspiel: Dank eindeutiger Adressbereiche auf beiden Seiten sind Adresskollisionen von vornherein ausgeschlossen und gordische NAT-Knoten daher nicht erforderlich. Die Konfiguration und das Troubleshooting solcher VPNs sind weit einfacher. Technisch gesehen muss nur das jeweils andere IPv6-Präfix im eigenen Netz geroutet werden – Ende-zu-Ende-IP-Verbindungen par excellence.
Vorteil 4: Stets genügend Platz in der DMZ
Viele Netzwerke sind organisch gewachsen und die ursprünglichen Konzepte zur Aufteilung des Adressraums genügen den aktuellen Anforderungen nicht mehr, denn auf einmal braucht die Firma mehr Server, als sich im dafür gedachten IPv4-Segment adressieren lassen.
Beispiel: Die Webserver-DMZ nutzt den Bereich 192.168.17.0/28, womit sich mitsamt dem Default-Gateway 14 Server adressieren lassen: 192.168.17.1 – 192.168.17.14. Sollen nun weitere Server hinzukommen, fehlt es an Adressen. Eine Neuaufteilung der Subnetze zur Vergrößerung des DMZ-Adressbereichs ist in großen Netzwerken kaum möglich.
Aber Not macht erfinderisch und risikobereit: Manche Admins legen im gleichen Layer-2-Segment ein zweites IP-Netz an, beispielsweise 192.168.91.64/28. Darin bekommt die Firmen-Firewall eine zweite IP-Adresse, damit sie für das zweite Netz als Default-Gateway arbeiten kann (192.168.91.65). So lassen sich weitere 13 Server adressieren. Das funktioniert zwar, erhöht aber die Komplexität, weshalb man solche Szenarien lieber meidet.
Mit IPv6 kommt man um solche Verknotungen auf absehbare Zeit leicht herum, weil die Adressräume weit größer sind: Mit jedem /64er-Subnetz lassen sich bis zu 2^64 Geräte adressieren. Ausgeschrieben: 18.446.744.073.709.551.616. Der Layer-2-Switch, der so viele MAC-Adressen verwalten kann, muss erst noch gebaut werden. Für MAC-Adressen sind bisher nur Tabellen mit 8192 bis 65.536 Einträgen üblich, und zwar für alle VLANs zusammengenommen.
Vorteil 5: Routing-Tabellen überblicken
Admins, die mit IPv4 aufgewachsen sind, haben verinnerlicht, mit Adressen zu knausern. Oder anders gesagt: kein Netz größer zu machen als unbedingt nötig. Deshalb bestehen unter anderem DMZ-Subnetze aus unterschiedlichen Teilnetzen wie /27, /28 oder /29er, während Gäste-WLANs oft auf /23- oder /22-Blöcke ausgedehnt sind – sehr zum Leidwesen des Netzadmins, der Routing-Tabellen nicht mal eben mit einem grep-Kommando durchforsten kann.
Stattdessen muss er die Subnetzmaske durchblicken. Hat der Admin in der Routing-Tabelle drei Netze, kann er nicht einfach per grep 192.168.23. herausfiltern, welche der Routen denn stimmt. Er muss alle drei anschauen und verstehen. Und wenn die Routing-Tabelle aus mehreren Hundert Einträgen besteht, hilft Drübergucken auch nicht mehr, sondern nur noch spezielle Lookup-Tools, wie sie Router oder Firewalls bieten.
Das ist umständlich. Anders bei IPv6: Die ersten vier Hextets einer IPv6-Adresse bezeichnen immer und eindeutig die Netz-ID. Die Zugehörigkeit von Node-IDs zu einem Netz ist daher unmittelbar ersichtlich, egal, ob in Routing-Tabellen oder Firewall-Logs.
Vorteil 6: Ende-zu-Ende-Verbindungen
Bereits bei der Spezifikation vor fast 30 Jahren werteten Fachleute die NAT als “short-term solution” und favorisierten ein künftiges Internet-Protokoll mit größerem Adressraum. Denn wenn eine NAT im Spiel ist, können IPv4-Geräte keine Ende-zu-Ende-Verbindungen aufbauen. Deshalb lassen sich Server-Logs nicht umgehend einer Client-Session zuordnen. Der NAT-Router muss den Zustand (state) in der NAT-Tabelle pflegen und unbenutzte Sessions tilgen, andernfalls können irgendwann keine neuen Sessions aufgebaut werden.
Kurzum: Die NAT hat zwar eine Zeit lang geholfen, das Internet-Wachstum aufrechtzuerhalten, aber daran festzuhalten heißt auch, mehr Geld für heutzutage rare IPv4-Adressen ausgeben. Bei eingehenden Verbindungen zu einem Server entfernt sie die öffentliche IPv4-Adresse aus dem Header des Client-Pakets, setzt die private IP-Adresse des Servers ein, notiert sich das und gibt das Paket schließlich zum Server weiter. Das belastet den Router und bremst den Verkehr.
Diesen kosten- und energieträchtigen Rechenaufwand kann man Routern durch den Wechsel auf IPv6 ersparen. Dank weltweit eindeutiger Adressierung aller Endgeräte braucht IPv6 keine NAT – ein Router muss die Pakete nur noch routen. So war ursprünglich auch das IPv4-Internet gedacht.
Wer sich um die Security Sorgen macht, da alle IPv6-Clients adressierbar sind: addressable ≠ accessible! Eine Firewall, die unverlangt eingehende Verbindungen verwirft, stellt sicher, dass interne Geräte der Firma eben nicht von außen erreichbar sind. Anstelle eines einfachen Routers mit seiner durchsatzbegrenzenden NAT kommt eine echte Firewall zum Einsatz. Schon die allermeisten einfachen Router für den Heimbereich sind IPv6-seitig genau so ausgelegt und schützen das Netz ab Werk, also ohne jegliche Benutzerinteraktion. Beispielsweise machen die verbreiteten die Fritzboxen genau das.
Vorteil 7: Kein Split-DNS
Damit externe Clients auf Server mit privaten IPv4-Adressen zugreifen können, die hinter einer NAT stehen, befragen sie zunächst das Domain Name System (DNS) nach der öffentlichen IP-Adresse der angesteuerten Domain. Im öffentlichen DNS stehen keine privaten IPv4-Adressen, sodass dort der angefragte Domainname auf die öffentliche IPv4-Adresse des Routers gemappt ist.
Interne Clients sollen aber möglichst nicht den Weg über die NAT gehen, um den Router zu entlasten. Damit sie den kurzen internen Weg beschreiten, richtet man im Netz einen internen DNS-Server ein, der den Clients die private IPv4-Adresse des Servers liefert, den sie dann direkt kontaktieren. So gibt es aber je nach Position eines Clients unterschiedliche DNS-Server mit unterschiedlichen Antworten auf dieselbe DNS-Anfrage – das ist die klassische und zurecht ungeliebte Split-DNS-Konfiguration mit zwei (oder sogar mehr) Views.
IPv6 benötigt keine NAT, sodass für alle Server die öffentliche IPv6-Adresse direkt auf ihren Netzwerkkarten konfiguriert ist. Deshalb erfolgen IPv6-Zugriffe von Clients auf Server im selben Netz sowieso direkt, weil die Wege zu den Servern in der internen Route stehen. Das erspart das Split-DNS – eine Fehlerquelle weniger.
Vorteil 8: Viele Server auf gleichen Ports
Privatkunden und auch viele Kleinunternehmen erhalten in der Regel Internetanschlüsse mit nur einer öffentlichen IPv4-Adresse– wenn überhaupt, Kabel-Internet mit DS-Lite und Glasfaserzugänge mit CG-NAT lassen grüßen. Mit einer IPv4-Adresse kann man pro TCP/UDP-Port normalerweise nur einen Server betreiben, also zum Beispiel nur einen HTTPS-Server auf 443/TCP oder nur einen SMTP-Server auf 25/TCP.
Wenn auf demselben Anschluss auch IPv6 geschaltet ist, kann man dahinter mehrere Server auf denselben Ports betreiben. Entwickler können so mehrere Server unter verschiedenen IPv6-Adressen für verschiedene Zwecke laufen lassen, zum Beispiel für die Produktion und den Testbetrieb, oder Haupt- und Backup-Server für SMTP- und IMAP-Mail.
Vorteil 9: Infos im Suffix abbilden
Enterprise-Router haben wie andere IPv6-Hosts auch für jedes Interface mindestens zwei IPv6-Adressen, eine Link-lokale und eine globale. Die Suffixe – der Host-Teil, auch IID, hintere 64 Bit – der Adressen generiert ein Router automatisch, wenn man ihn lässt; er leitet sie von der MAC-Adresse des jeweiligen LAN-Interfaces ab (modifiziertes EUI-64-Verfahren für Interface Identifiers in RFC 4291). Diese automatisch generierten Suffixe sind aber schwer zu merken, was zum Beispiel die Fehlersuche erschwert. Womöglich ist das eine der Ursachen, dass sich Admins für IPv6 so schwer erwärmen.
Die Übersicht lässt sich leicht verbessern, indem man im Suffix Gebäude-, Stockwerk-, Abteilungsstrukturen oder gar den Router-Typ manuell abbildet und zwar so, dass Sie sich die Zuordnungen leicht memorieren können. Da man für Server-Host-IDs nur wenige Stellen benötigt, können Sie drei der vier Host-ID Bereiche wegkürzen. Angenommen, das Serverpräfix lautet 2001:db8:f5:1234::/64, dann vergibt man in diesem Subnetz für die Server beispielsweise 2001:db8:f5:1234::a1, 2001:db8:f5:1234::a2, und so weiter. Um die Hosts zu unterscheiden, genügt also ein Blick auf das letzte Hextet der Host-ID.
Auch ist nützlich, dasselbe Suffix in der Link-lokalen Adresse zu verwenden. Wenn Sie die wesentlichen Merkmale in den letzten 32 Bit des Suffix kodieren, können Sie diesen Bereich bei den Routing-Protokollen OSPFv3 und BGP zusätzlich als Router-ID nutzen.
Vorteil 10: Hierarchischer Adressplan
Von den Vorteilen eines hierarchischen IPv6-Adressplans haben wir hier noch gar nicht gesprochen. Beispielsweise gibt es die Möglichkeit, an den Nibble-Boundaries (4-Bit-Blöcke zur Subnetierung) eines /32er-Präfixes die /48er-Sites zu nummerieren. Oder innerhalb eines /48-Blocks die /64er-Subnetze anhand der Organisationseinheiten oder Securityzonen zu ordnen. Das ist ein anderes Thema, dem auch schon ganze Bücher gewidmet sind.
Zur Liste der Vorteile muss man fairerweise noch sagen, dass nicht alle bei jeder Anwendung greifen. Im privaten Heimnetz sind DNS-Views (siehe Vorteil 7) meistens unwichtig, zumal schon die Anzahl an verschiedenen Subnetzen (5) niedrig ist. In großen, weltweit aufgestellten Unternehmen ist wiederum das einfache Routing (2) über VPNs nicht mehr skalierbar beziehungsweise politisch oder organisatorisch schwer umzusetzen.
Dennoch: Die Vorteile des IPv6-Adressraums sind weit größer als die reine Anzahl adressierbarer Endgeräte.
Erste Schritte
Letztlich bleibt der Widerwille gegen hexadezimale IPv6-Adressen ein nicht haltbares Vorurteil. Lassen Sie sich also nicht davon irritieren. Unsere Empfehlung lautet: Starten Sie mit IPv6. Es muss ja nicht gleich das gesamte Firmennetz sein. Ein kleines Labor, das Gäste-WLAN oder eine DMZ genügen, um Erfahrungen zu sammeln. So gewöhnen sich Admins leicht an IPv6-Adressen in Routing-Tabellen, Firewall-Regelwerken und Applikations-Logs. Das verkleinert die Hürde, falls IPv6 morgen zwingend erforderlich wird.
Und wenn Sie sich entschieden haben, IPv4 aufs Reservegleis zu schieben: Planen Sie Ihre IPv6-Infrastruktur am besten von Grund auf neu, ohne Bezugnahme auf Ihre IPv4-Struktur. Viele Netze sind im Laufe der Jahre organisch gewachsen und aus heutiger Sicht nicht mehr optimal strukturiert. Nutzen Sie den Umstieg, um das Dickicht zu lichten.
Die Abbildung Ihrer Prozesse auf IPv6 dürfte in den allermeisten Fällen reibungslos klappen, weil inzwischen der Großteil der Anwendungen auf IPv6 läuft. Kalkulieren Sie Mehraufwand ein, um individuelle Lösungen wie Skripte für IPv6 zu ertüchtigen.
Achten Sie beim Parallelbetrieb von IPv6 und IPv4 darauf, dass alle Sicherheitsrichtlinien umgesetzt sind. Ein beliebter Fehler: Man schränkt zwar den SSH-Login auf der externen Firewall für IPv4 per Access List auf bestimmte IPv4-Quelladressen ein, vergisst aber, den Zugriff für IPv6 zu beschränken, sodass der SSH-Server per IPv6 aus dem gesamten Internet erreichbar ist.
Zu beachten ist auch, dass Server, die über ein VPN per IPv6 angesprochen werden und in einer DMZ stehen, einem Sicherheitsrisiko ausgesetzt sind. Bricht der Tunnel zusammen, funktioniert die VPN-Route nicht mehr und der Verkehr geht ersatzweise über die Default Route zum Ziel. Dabei laufen Anwendungen, die nicht von sich aus verschlüsseln, blank übers Internet (z. B. IP-Telefonie oder Mail-Verkehr). Dagegen helfen bei großen Firewalls spezielle Regeln.
Exkurs: Die Nachteile der NAT
Im letzten Jahrtausend gab es tatsächlich eine Phase, als jeder Host im IPv4-basierten Internet seine eigene öffentliche Adresse hatte. Als das Wachstum alle Erwartungen übertraf, zauberten findige Entwickler die Network Address Translation (NAT) aus dem Ärmel und brachten so mittels privaten, öffentlich nicht gerouteten Adressen ein Mehrfaches an Netzwerkgeräten ins Internet, als mit den 4,3 Milliarden IPv4-Adressen möglich ist. Das ist nun der Status: NAT hat sich fürs IPv4-Internet unverzichtbar gemacht.
Doch damit sie zwischen Geräten mit privaten IPv4-Adressen im Netzwerk und Zielen im öffentlichen Internet vermitteln kann, ändert die NAT die Ziel- und Quelladressen von ein- und ausgehenden Datenpaketen, notiert sich für jede einzelne Sitzung die Bezüge und reicht die Pakete dann erst zu ihren Zielen weiter. Daraus entstehen Nachteile, die man teils wiederum mit Behelfen mehr schlecht als recht kompensiert.
Hosts in verschiedenen Netzen, die hinter NATs stehen, können nicht direkt miteinander kommunizieren, da die NATs unaufgefordert eingehende Verbindungen verwerfen. Damit sie wenigstens mittelbar kommunizieren können, braucht man Hilfsprotokolle wie STUN, TURN, ICE oder UPnP. Manche sind umständlich zu konfigurieren und sie funktionieren nicht immer. Beispielsweise gibt es Router, die für ihre interne VoIP-TK-Anlage alle VoIP-Sessions (SIP und RTP) für sich beanspruchen, sodass man dahinter keine eigene VoIP-TK-Anlage betreiben kann.
NAT-Tabellen können nicht beliebig groß sein. Meistens fassen sie nur einige Tausend Einträge, denn Router müssen mit ihrem meist knappen RAM-Angebot haushalten. Deshalb löschen sie inaktive NAT-Einträge bei Platznot. Um Einträge so lange aktuell zu halten, wie die jeweilige IP-Sitzung dauert, müssen Netzwerkgeräte etwa im Minutentakt Pakete zu ihrem Ziel senden, die dem Router signalisieren: “Dieser NAT-Eintrag wird noch benötigt”. Das tun nicht alle Anwendungen. Beispielsweise senden Messaging- oder Notification-Anwendungen Daten nur unregelmäßig, sodass ihr NAT-Eintrag verschwindet. Daher sind manche solcher Clients nicht durchgängig erreichbar oder müssen ihre Verbindung immer wieder neu aufbauen.
Umgekehrt gilt: Wenn die Netzwerkgeräte viele Sitzungen dauerhaft aufgebaut haben, kann die NAT-Tabelle überlaufen, mit der Folge, dass manche Sitzungen unerwartet abbrechen (z. B. VPN-Tunnel).
Zu dem Thema haben Fachleute schon ganze Bücher geschrieben, es gibt sogar ein IETF-Dokument, das ausschließlich den Problemen gewidmet ist, das die NAT verursacht (RFC 3027). Unterm Strich gilt: Die NAT ist okay, solange man auf IPv4 angewiesen ist. Doch die Behauptung, “NAT ist ein Security-Feature” hat nie gestimmt. Wenn möglich, sollte man also auf IPv6 umsteigen, weil sich damit viele Detailprobleme gar nicht erst stellen.
From time to time I stumble upon Tweets about counting the number of IPv6 addresses (123). While I think it is ok to do it that way when you’re new to IPv6 and you want to get an idea of it, it does not make sense at all because the mere number of IPv6 addresses is ridiculously high and only theoretically, but has no relevance for the real-world at all. Let me state why:
First of all, the basic concept of IPv6 is not about the number of addresses such as “how to choose the subnet size appropriate to the number of clients I’m expecting”, but about the number of prefixes such as “how to subdivide my overall network into logical areas like security zone or business units”. It’s not about concrete IPv6 addresses at all. For each of your /64 subnets, which is the one and only subnet size you should ever use, you have 2^64 host addresses, which is de facto indefinitely.
The underlying network infrastructure must somehow deal with the number of addresses. Most commonly Ethernet is used, which relies on MAC addresses. Switches have to take care of their MAC address tables, while routers are using the neighbor cache (the equivalent to the ARP cache for legacy IP) to know where to forward the Ethernet frame. Obviously, every single IPv6 address must be in the neighbor cache of a router. And those tables are limited in space, which is at most something like 512 k entries nowadays. You can argue that you can route an entire /64 to a single machine, using those addresses for vhosts or containers or something like this. Though, in the end, we won’t see many more than a couple of thousands of unique IPv6 addresses per subnet as they still require a state to be maintained.
In the end, this topic is about legacy IP problems. We have all been into IPv4 thinking for several years or even decades. Now with IPv6, it’s not only about different-looking addresses but about completely new addressing schemes. We don’t have the IPv4 CIDR chart anymore (listing the number of IPv4 addresses per subnet), but the IPv6 chart (listing the number of smaller prefixes within a bigger one). Please, get rid of IPv4 thinking and start with new approaches from scratch. It will blow your mind. ;)
For some reason, I came across a blog post by Gian Paolo called Small servers. This reminded me of some fairly old network protocols (that no one uses as far as I know) that are not in my Ultimate PCAP yet. Hence I took some minutes, captured them, and took some Wireshark screenshots. They are: echo, discard, daytime, chargen, and time. Mostly via TCP and UDP, and, as you would have expected, IPv6 and legacy IP.
I’m aware that this is not of interest to most of you. :) But for the sake of completeness, and because I love adding new protocols to the Ultimate PCAP, I added them though.
I used an old Cisco 2811 router with IOS version 15.1(4)M12a for this:
service udp-small-servers
service tcp-small-servers
For the daytime to work with UDP, I queried my Meinberg LANTIME M200 at ntp3.weberlab.de (AAAA) and ntp3-legacy-ip.weberlab.de (A) respectively. Furthermore, I also queried the “time” protocol, port number 37, against the Meinberg since it is not implemented by Ciscos small-servers.
Some Nmap scans, just for reference:
weberjoh@h2877111:~$ nmap -6 router1.weberlab.de
Starting Nmap 7.80 ( https://nmap.org ) at 2022-10-20 13:08 CEST
Nmap scan report for router1.weberlab.de (2001:470:1f0a:319::2)
Host is up (0.033s latency).
Other addresses for router1.weberlab.de (not scanned): 37.24.166.89
rDNS record for 2001:470:1f0a:319::2: tunnel643592-pt.tunnel.tserv6.fra1.ipv6.he.net
Not shown: 996 closed ports
PORT STATE SERVICE
7/tcp open echo
9/tcp open discard
13/tcp open daytime
19/tcp open chargen
Nmap done: 1 IP address (1 host up) scanned in 8.79 seconds
weberjoh@h2877111:~$
weberjoh@h2877111:~$
weberjoh@h2877111:~$ nmap router1.weberlab.de
Starting Nmap 7.80 ( https://nmap.org ) at 2022-10-20 13:07 CEST
Nmap scan report for router1.weberlab.de (37.24.166.89)
Host is up (0.047s latency).
Other addresses for router1.weberlab.de (not scanned): 2001:470:1f0a:319::2
rDNS record for 37.24.166.89: ip-037-024-166-089.um08.pools.vodafone-ip.de
Not shown: 996 closed ports
PORT STATE SERVICE
7/tcp open echo
9/tcp open discard
13/tcp open daytime
19/tcp open chargen
Nmap done: 1 IP address (1 host up) scanned in 5.82 seconds
weberjoh@h2877111:~$
weberjoh@h2877111:~$
weberjoh@h2877111:~$ sudo nmap -6 -sU -p 7,9,13,19 router1.weberlab.de
Starting Nmap 7.80 ( https://nmap.org ) at 2022-10-20 13:19 CEST
Nmap scan report for router1.weberlab.de (2001:470:1f0a:319::2)
Host is up (0.10s latency).
Other addresses for router1.weberlab.de (not scanned): 37.24.166.89
rDNS record for 2001:470:1f0a:319::2: tunnel643592-pt.tunnel.tserv6.fra1.ipv6.he.net
PORT STATE SERVICE
7/udp open echo
9/udp closed discard
13/udp closed daytime
19/udp closed chargen
Nmap done: 1 IP address (1 host up) scanned in 2.15 seconds
weberjoh@h2877111:~$
weberjoh@h2877111:~$
weberjoh@h2877111:~$ sudo nmap -sU -p 7,9,13,19 router1.weberlab.de
Starting Nmap 7.80 ( https://nmap.org ) at 2022-10-20 13:18 CEST
Nmap scan report for router1.weberlab.de (37.24.166.89)
Host is up (0.030s latency).
Other addresses for router1.weberlab.de (not scanned): 2001:470:1f0a:319::2
rDNS record for 37.24.166.89: ip-037-024-166-089.um08.pools.vodafone-ip.de
PORT STATE SERVICE
7/udp open echo
9/udp open|filtered discard
13/udp closed daytime
19/udp open|filtered chargen
Nmap done: 1 IP address (1 host up) scanned in 10.70 seconds
weberjoh@h2877111:~$
weberjoh@h2877111:~$
weberjoh@h2877111:~$ sudo nmap -6 -sU -p 13 ntp3.weberlab.de
Starting Nmap 7.80 ( https://nmap.org ) at 2022-11-18 08:55 CET
Nmap scan report for ntp3.weberlab.de (2001:470:1f0b:16b0::dcfb:123)
Host is up (0.022s latency).
PORT STATE SERVICE
13/udp open daytime
Nmap done: 1 IP address (1 host up) scanned in 4.21 seconds
weberjoh@h2877111:~$
pi@pi05-random:~ $
pi@pi05-random:~ $ sudo nmap -sU -p 13 ntp3-legacy-ip.weberlab.de
Starting Nmap 7.40 ( https://nmap.org ) at 2022-11-18 11:55 CET
Nmap scan report for ntp3-legacy-ip.weberlab.de (194.247.5.12)
Host is up (0.00048s latency).
PORT STATE SERVICE
13/udp open daytime
MAC Address: 00:13:95:24:34:04 (congatec AG)
Nmap done: 1 IP address (1 host up) scanned in 1.33 seconds
Calling Them: Basically Telnet
To be honest, all of those protocols basically rely on mere TCP or UDP, just like HTTP or SMTP or all the other plaintext protocols out there. That is:
telnet and
netcat for these scenarios here. Now for all those 5 protocols, I did 4x calls each, namely TCP for IPv6 and legacy IP, as well as UDP for IPv6 and legacy IP. I referenced the protocols by either their name or their numerical number: (Reminder: Exiting telnet with ^] which is “Strg +” on a german keyboard.)
###echo
#exiting telnet with "Strg +" and "quit"
telnet router1.weberlab.de echo
telnet -4 router1.weberlab.de echo
netcat -u router1.weberlab.de 7
netcat -4 -u router1.weberlab.de 7
###discard
#exiting telnet with "Strg +" and "quit"
telnet router1.weberlab.de discard
telnet -4 router1.weberlab.de discard
netcat -u router1.weberlab.de 9
netcat -4 -u router1.weberlab.de 9
###daytime
#exiting telnet with "Strg +" and "quit"
telnet router1.weberlab.de daytime
telnet -4 router1.weberlab.de daytime
telnet ntp3.weberlab.de 13
telnet ntp3-legacy-ip.weberlab.de 13
#UDP needs an enter key to respond
netcat -u ntp3.weberlab.de 13
netcat -u ntp3-legacy-ip.weberlab.de 13
###chargen
#exiting telnet with "Strg +" and "quit"
telnet router1.weberlab.de chargen
telnet -4 router1.weberlab.de chargen
netcat -u router1.weberlab.de 19
netcat -4 -u router1.weberlab.de 19
###time
#exiting telnet with "Strg +" and quit
telnet ntp3.weberlab.de time
telnet ntp3-legacy-ip.weberlab.de time
#UDP needs an enter key to respond
netcat -u ntp3.weberlab.de 37
netcat -u ntp3-legacy-ip.weberlab.de 37
The complete story is this:
weberjoh@h2877111:~$ telnet router1.weberlab.de echo
Trying 2001:470:1f0a:319::2...
Connected to router1.weberlab.de.
Escape character is '^]'.
hello world
hello world
yup
yup
here we go
here we go
^]
telnet> quit
Connection closed.
weberjoh@h2877111:~$ telnet -4 router1.weberlab.de echo
Trying 37.24.166.89...
Connected to router1.weberlab.de.
Escape character is '^]'.
same here
same here
but with legacy IP ;D
but with legacy IP ;D
^]
telnet> quit
Connection closed.
weberjoh@h2877111:~$ netcat -u router1.weberlab.de 7
what about UDP
what about UDP
yeah
yeah
^C
weberjoh@h2877111:~$ netcat -4 -u router1.weberlab.de 7
as well as for legacy IP here
as well as for legacy IP here
ciao
ciao
^C
weberjoh@h2877111:~$ telnet router1.weberlab.de discard
Trying 2001:470:1f0a:319::2...
Connected to router1.weberlab.de.
Escape character is '^]'.
discarding everything
^]
telnet> quit
Connection closed.
weberjoh@h2877111:~$ telnet -4 router1.weberlab.de discard
Trying 37.24.166.89...
Connected to router1.weberlab.de.
Escape character is '^]'.
foo bar
^]
telnet> quit
Connection closed.
weberjoh@h2877111:~$ netcat -u router1.weberlab.de 9
was sollen wir trinken?
weberjoh@h2877111:~$ netcat -4 -u router1.weberlab.de 9
sieben Tage lang
was sollen wir trinken?
so ein Durst!
^C
weberjoh@h2877111:~$ telnet router1.weberlab.de daytime
Trying 2001:470:1f0a:319::2...
Connected to router1.weberlab.de.
Escape character is '^]'.
Friday, November 18, 2022 13:03:03-CET
Connection closed by foreign host.
weberjoh@h2877111:~$ telnet -4 router1.weberlab.de daytime
Trying 37.24.166.89...
Connected to router1.weberlab.de.
Escape character is '^]'.
Friday, November 18, 2022 13:03:12-CET
Connection closed by foreign host.
weberjoh@h2877111:~$ telnet ntp3.weberlab.de 13
Trying 2001:470:1f0b:16b0::dcfb:123...
Connected to ntp3.weberlab.de.
Escape character is '^]'.
18 NOV 2022 12:03:18 UTC
Connection closed by foreign host.
weberjoh@h2877111:~$ telnet ntp3-legacy-ip.weberlab.de 13
Trying 194.247.5.12...
Connected to ntp3-legacy-ip.weberlab.de.
Escape character is '^]'.
18 NOV 2022 12:03:21 UTC
Connection closed by foreign host.
weberjoh@h2877111:~$ netcat -u ntp3.weberlab.de 13
18 NOV 2022 12:03:26 UTC
18 NOV 2022 12:03:27 UTC
18 NOV 2022 12:03:29 UTC
18 NOV 2022 12:03:30 UTC
18 NOV 2022 12:03:30 UTC
18 NOV 2022 12:03:30 UTC
18 NOV 2022 12:03:30 UTC
18 NOV 2022 12:03:30 UTC
^C
weberjoh@h2877111:~$ netcat -u ntp3-legacy-ip.weberlab.de 13
^C
weberjoh@h2877111:~$ telnet router1.weberlab.de chargen
Trying 2001:470:1f0a:319::2...
Connected to router1.weberlab.de.
Escape character is '^]'.
!"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefg
!"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefgh
"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghi
#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghij
$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijk
%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijkl
&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklm
'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmn
()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmno
)*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnop
*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopq
+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqr
,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrs
-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrst
./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstu
^]
telnet> quit
Connection closed.
weberjoh@h2877111:~$ telnet -4 router1.weberlab.de chargen
Trying 37.24.166.89...
Connected to router1.weberlab.de.
Escape character is '^]'.
!"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefg
!"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefgh
"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghi
#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghij
$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijk
%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijkl
&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklm
'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmn
()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmno
)*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnop
*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopq
+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqr
,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrs
-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrst
./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstu
/0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuv
^]
telnet> quit
Connection closed.
weberjoh@h2877111:~$ netcat -u router1.weberlab.de 19
weberjoh@h2877111:~$ netcat -4 -u router1.weberlab.de 19
asdf
^C
weberjoh@h2877111:~$ telnet ntp3.weberlab.de time
Trying 2001:470:1f0b:16b0::dcfb:123...
Connected to ntp3.weberlab.de.
Escape character is '^]'.
▒!▒<Connection closed by foreign host.
weberjoh@h2877111:~$ telnet ntp3-legacy-ip.weberlab.de time
Trying 194.247.5.12...
Connected to ntp3-legacy-ip.weberlab.de.
Escape character is '^]'.
▒!▒@Connection closed by foreign host.
weberjoh@h2877111:~$ netcat -u ntp3.weberlab.de 37
▒!▒D
▒!▒E
▒!▒F^C
weberjoh@h2877111:~$ netcat -u ntp3-legacy-ip.weberlab.de 37
^C
weberjoh@h2877111:~$
Note that the “time” protocol is the only one which does not display ASCII characters in the telnet session, but kind of junk. ;) This is due to its format: “The server then sends the time as a 32-bit unsigned integer in binary format and in network byte order, representing the number of seconds since 00:00 (midnight) 1 January, 1900 GMT.”
Under the Magnifying Glass: Wireshark
Let’s have a brief look at those protocols with Wireshark.
Remember when using display filters within Wireshark: Using the protocol name itself such as
echoonly displays the mere protocol-specific packets, but not the stuff around it like the TCP handshake and so on. If you would like to see the whole thing, you must use something like
tcp.port eq 7 .
Echo
The Echo protocol simply sends back everything it has received. Specified in RFC 862. Fun fact: The whole RFC is only ONE PAGE!!!
As you can see in the screenshot, I’ve done it via TCP and UDP, both for IPv6 and legacy IP. A good time to point to the “Follow TCP Stream” or “Follow UDP Stream” again:
Discard
Uh, as of now (November 2022), Wireshark does not yet recognize the “Discard” protocol at port 9. I added a feature request here. Use this display filter to find it nevertheless:
tcp.port eq 9 or udp.port eq 9
The Discard service, RFC 863, simply discards everything it has received. For TCP, everything is ACKed at least (no data is sent back, though), while for UDP you won’t see any packets from the server. However, seems like my router did not listen on the Discard port 9 for UDP on IPv6, since an ICMPv6 destination unreachable -> port unreachable came back:
Daytime
“A daytime service simply sends the current date and time as a character string without regard to the input”, RFC 867. Different implementations send different structures of pure ASCII letters:
Chargen
The Character Generator Protocol “simply sends data without regard to the input”, RFC 864. My Cisco router only replied by TCP though. Good example to “Follow TCP Stream” again:
Time
Finally, the Time protocol on port 37, RFC 868, returns the number of seconds since 01.01.1900. Wireshark decodes it:
The End
And yes, at the very end, I disabled those small-servers again on the Cisco router:
no service udp-small-servers
no service tcp-small-servers
The other day I just wanted to capture some basic Linux traceroutes but ended up troubleshooting different traceroute commands and Wireshark display anomalies. Sigh. Anyway, I just added a few Linux traceroute captures – legacy and IPv6 – to the Ultimate PCAP. Here are some details:
Yep, I was shocked myself, but while I had some Windows traceroutes (based on ICMP echo-requests) and even some layer 4 traceroutes (sending TCP SYNs, e.g.) in the Ultimate PCAP, I was missing a generic Linux traceroute that uses UDP datagrams to destination ports ≥ 33434 for it. So, here we are.
Traceroute with Legacy IP
I used an Ubuntu 16.04.7 LTS (GNU/Linux 4.4.0-234-generic x86_64):
weberjoh@nb15-lx:~$ traceroute -V
Modern traceroute for Linux, version 2.0.21
Copyright (c) 2008 Dmitry Butskoy, License: GPL v2 or any later
weberjoh@nb15-lx:~$
weberjoh@nb15-lx:~$
weberjoh@nb15-lx:~$ traceroute netsec.blog
traceroute to netsec.blog (5.35.226.136), 30 hops max, 60 byte packets
1 192.168.3.1 (192.168.3.1) 14.003 ms 13.960 ms 13.932 ms
2 ip-037-024-166-081.um08.pools.vodafone-ip.de (37.24.166.81) 15.423 ms 16.794 ms 15.892 ms
3 ip-178-200-118-001.um45.pools.vodafone-ip.de (178.200.118.1) 29.912 ms 33.328 ms 33.087 ms
4 ip-081-210-129-132.um21.pools.vodafone-ip.de (81.210.129.132) 32.901 ms 33.709 ms 33.813 ms
5 de-fra04d-rc1-ae-7-0.aorta.net (84.116.197.245) 41.520 ms 41.025 ms 40.964 ms
6 de-fra04c-ri1-ae15-101.aorta.net (84.116.191.6) 37.400 ms 18.572 ms 18.346 ms
7 et-7-0-0-u100.fra1-cr-polaris.bb.gdinf.net (80.81.192.239) 20.243 ms 20.314 ms 20.112 ms
8 ae0.fra10-cr-antares.bb.gdinf.net (87.230.115.1) 20.941 ms 20.509 ms 24.838 ms
9 ae2.cgn1-cr-nashira.bb.gdinf.net (87.230.114.4) 25.985 ms 26.216 ms 26.038 ms
10 ae0.100.sr-jake.cgn1.dcnet-emea.godaddy.com (87.230.114.222) 38.922 ms 38.912 ms 24.242 ms
11 * * *
12 wp367.webpack.hosteurope.de (5.35.226.136) 23.472 ms 23.407 ms 19.353 ms
Pro-tip for Wireshark: Use a custom column which shows the hop limit (IPv6) and TTL (IPv4) in one column:
By default, traceroute sends three packets with the same hop limit/TTL starting by 1. This results in various UDP streams. At the time of writing with Wireshark version 4.0.1, the coloring of those packets is this: the first 12 UDP streams are marked red (TTL 1-4), while the other ones aren’t. (We are currently discussing the default coloring rules here at the Wireshark issues pages.) Right after it, the ICMP “time-to-live exceeded” error messages came in, while traceroute itself sent out various reverse DNS queries (omitted in the following screenshot):
Then it turned a little strange. I was always confused about which CLI command I should use for ping and/or traceroute for IPv6:
traceroute6 or
traceroute -6. The man page from traceroute states:
traceroute6 is equivalent to traceroute -6
While the man page from traceroute6 states:
Description can be found in traceroute(8), all the references to IP replaced to IPv6. It is needless to copy the description from there.
Hence they should definitely be the same, right? … Unfortunately, they aren’t.
This is a traceroute6 call:
weberjoh@nb15-lx:~$ traceroute6 -V
traceroute6 utility, iputils-s20121221
weberjoh@nb15-lx:~$
weberjoh@nb15-lx:~$
weberjoh@nb15-lx:~$ traceroute6 netsec.blog
traceroute to netsec.blog (2a01:488:42:1000:50ed:8588:8a:c570) from 2001:470:7250::b15:22, 30 hops max, 24 byte packets
1 pa-dmz.weberlab.de (2001:470:7250::1) 1.058 ms 0.287 ms 0.181 ms
2 router1-fa0-1.weberlab.de (2001:470:1f0b:319::1) 0.835 ms 1.234 ms 1.036 ms
3 tunnel643592.tunnel.tserv6.fra1.ipv6.he.net (2001:470:1f0a:319::1) 14.686 ms 16.142 ms 13.943 ms
4 * * *
5 et-7-0-0-u100.fra1-cr-polaris.bb.gdinf.net (2001:7f8::5125:f1:1) 12.482 ms 10.207 ms 11.824 ms
6 ae0.fra10-cr-antares.bb.gdinf.net (2a01:488:bb03:100::3) 19.943 ms 12.124 ms 11.887 ms
7 ae2.cgn1-cr-nashira.bb.gdinf.net (2a01:488:bb02:101::2) 11.712 ms 29.159 ms 17.87 ms
8 ae0.sr-jake.cgn1.dcn.heg.com (2a01:488:bb::223) 28.083 ms 16.166 ms 16.063 ms
9 * * *
10 * * *
11 * * *
12 * * *
13 * * *
14 * * *
15 * * *
16 * * *
17 * * *
18 * * *
19 * * *
20 * * *
21 * * *
22 * * *
23 * * *
24 * * *
25 * * *
26 * * *
27 * * *
28 * * *
29 * * *
30 * * *
(Don’t worry about the count to 30 hops for this. The destination or a firewall somewhere there is not responding, hence it counts to infinity which is 30 for traceroute.)
But within Wireshark, it looked like this (omitting the ICMPv6 messages here). That is: Only one static UDP destination port, hence only one UDP stream as seen by Wireshark. Furthermore, a different data portion:
(Don’t worry that no packets at all are marked red (compared to the legacy IP ones), this is part of this discussion as well. It might change with Wireshark versions > 4.0.)
That’s why I did a
traceroute -6, this time from another machine: Ubuntu 20.04.5 LTS (GNU/Linux 5.4.0 x86_64):
weberjoh@h2877111:~$ traceroute -V
Modern traceroute for Linux, version 2.1.0
Copyright (c) 2016 Dmitry Butskoy, License: GPL v2 or any later
weberjoh@h2877111:~$
weberjoh@h2877111:~$
weberjoh@h2877111:~$ traceroute -6 netsec.blog
traceroute to netsec.blog (2a01:488:42:1000:50ed:8588:8a:c570), 30 hops max, 80 byte packets
1 * * *
2 491.ae12.core-b1.as6724.net (2a01:238:b:105::1) 0.285 ms 0.271 ms 0.210 ms
3 110.ae14.bb-rt1-2.h20.r22.rs.ber.de.as6724.net (2a01:238:b:3901::1) 0.400 ms 0.343 ms 110.ae13.bb-rt1-1.e18.r23.rs.ber.de.as6724.net (2a01:238:b:3801::1) 0.537 ms
4 ae-0-88.bb-a.ak.ber.de.oneandone.net (2001:8d8:0:3::99) 0.852 ms 0.817 ms ae-1-88.bb-a.ak.ber.de.oneandone.net (2001:8d8:0:3::a1) 0.799 ms
5 ae-13.bb-a.tp.kae.de.net.ionos.com (2001:8d8:0:2::1d2) 14.510 ms 14.451 ms 14.365 ms
6 ae-2.bb-b.bs.kae.de.net.ionos.com (2001:8d8:0:5::4) 16.837 ms 16.863 ms 16.871 ms
7 ae-9.bb-b.fr7.fra.de.net.ionos.com (2001:8d8:0:2::11e) 16.884 ms 16.905 ms 16.964 ms
8 et-7-0-0-u100.fra1-cr-polaris.bb.gdinf.net (2001:7f8::5125:f1:1) 16.417 ms 16.441 ms 16.403 ms
9 ae0.fra10-cr-antares.bb.gdinf.net (2a01:488:bb03:100::3) 17.188 ms 17.259 ms 17.183 ms
10 ae2.cgn1-cr-nashira.bb.gdinf.net (2a01:488:bb02:101::2) 19.992 ms 19.405 ms 19.340 ms
11 ae0.sr-jake.cgn1.dcn.heg.com (2a01:488:bb::223) 59.756 ms 59.678 ms 59.631 ms
12 * * *
13 * * *
14 * * *
15 * * *
16 * * *
17 * * *
18 * * *
19 * * *
20 * * *
21 * * *
22 * * *
23 * * *
24 * * *
25 * * *
26 * * *
27 * * *
28 * * *
29 * * *
30 * * *
Which now looks more familiar compared to the traceroute for legacy IP:
TL;DR: Always use
ping and/or
traceroute with -6 or -4, rather than ping6/traceroute6. Or even better: use
mtr.
By the way: This is what the traffic log from a Palo Alto Networks NGFW looks like for those two tools:
Anyway, those traceroutes are now within the Ultimate PCAP along with the ICMPv6/ICMP errors coming back and the DNS queries made by those traceroute tools. Thus you can investigate them by yourself. Note that those Linux traceroutes are not a protocol by themselves, hence there is no direct display filter. You can use something like this:
udp.dstport in { 33434 .. 33534 } and ( ip.ttl < 31 || ipv6.hlim < 31 )
Want to join the discussion?
Some tweets about those investigations during the last weeks:
Ouch! The man page states "traceroute6 is equivalent to traceroute -6" and it's NOT! While "traceroute6" sends all datagrams to the same dst.port (same stream), "traceroute -6" sends each datagram to an increased dst.port (different streams). Different tools! #IPv6#detailspic.twitter.com/2k3qD6KpQj
In general, Network Address Translation (NAT) solves some problems but should be avoided wherever possible. It has nothing to do with security and is only a short-term solution on the way to IPv6. (Yes, I know, the last 20 years have proven that NAT is used everywhere every time. 😉) This applies to all kinds of NATs for IPv4 (SNAT, DNAT, PAT) as well as for NPTv6 and NAT66.
However, there are two types of NATs that do not only change the network addresses but do a translation between the two Internet Protocols, that is IPv4 <-> IPv6 and vice versa. Let’s focus on NAT46 this time. In which situations is it used and why? Supplemented by a configuration guide for the FortiGates, a downloadable PCAP and Wireshark screenshots.
NAT46 Concept
Don’t get confused: I’m talking about NAT46 this time – not NAT64.
Basically, if you have IPv6-only servers (to avoid the unnecessary dual-stack burden for at least some of your infrastructure), but still want to have those servers accessible for IPv4-only clients, you have to use some kind of protocol translation somewhere. Either through reverse proxies or load balancers or through a NAT46 gateway like this:
Note that the NAT46 proxy, pronounced NAT-four-six by the way, does not necessarily have to be in the direct path between the client and server – it only has to be accessible by appropriate routes. Nevertheless, having one central firewall in place which does the job fits perfectly for small installations.
Furthermore, note that you need a hostname in the public DNS with an A record for the IPv4 address on your NAT46 gateway. But you don’t need a special DNS device such as a DNS64 box for NAT64 to work.
The basic concept of translating IP and ICMP between IPv4 and IPv6 aka “Stateless IP/ICMP Translation Algorithm (SIIT)” is described in RFC 7915. Funnily enough, the keyword “NAT46” is not said in the document at all.
I’m not a big fan of FortiGate firewalls because they are neither reliable nor sound in many situations. However, they offer many cool and new features that other vendors don’t have. So let’s configure NAT46. I’m using a FortiWiFi-61E with FortiOS v7.0.9 for this setup.
At first, it requires a NAT object aka “Virtual IP” of type IPv4 which maps the (public) IPv4 address to the (internal) IPv6 address:
Second, you need an IPv6 Pool for the IPv6 source from which the firewall will initiate the internal IPv6 connections. Note the NAT46 checkbox. Also note that the “pool” is not really a pool but only capable of one or two IPv6 addresses. It took me a while to figure it out. All ranges I tested weren’t valid until I reduced the pool to one single IPv6 address. As you can see, I chose a very special-looking one: an IPv6 address with 4646 at the very end to spot it easily:
Finally, you need an appropriate Firewall Policy. Note that you must select the “NAT46” feature before you can select the destination which is the virtual IP object:
I’m a little scared when looking at this policy in the overview since the destination IPv6 address object says “any” though nothing was selected when creating the policy. AHH. It looks like this policy now allows all IPv6 destinations. Hopefully, it doesn’t. (That’s what I mean when stating that FortiGate firewalls are not that sound.)
Having a look at the Forward Traffic Log you can indeed see both Internet Protocols:
The appropriate CLI commands for this feature are: (You have to adjust some of them according to your needs/setup, e.g., the profile-group, the inspection-mode, and the like.)
config firewall vip
edit "random46"
set comment "Test NAT46"
set extip 194.247.5.23
set nat44 disable
set nat46 enable
set extintf "wan1"
set ipv6-mappedip 2001:470:1f0b:16b0:6986:b8d4:3649:9cbe
next
end
config firewall ippool6
edit "SNAT46"
set startip 2001:470:1f0b:16b0::4646
set endip 2001:470:1f0b:16b0::4646
set nat46 enable
next
end
config firewall policy
edit 41
set name "random46"
set srcintf "wan1"
set dstintf "internal"
set action accept
set nat46 enable
set srcaddr "all"
set dstaddr "random46"
set srcaddr6 "all"
set dstaddr6 "all"
set schedule "always"
set service "HTTP" "HTTPS" "PING" "PING6"
set utm-status enable
set inspection-mode proxy
set profile-type group
set profile-group "app-only"
set logtraffic all
set ippool enable
set poolname6 "SNAT46"
next
end
Having a look at the sessions via CLI, you can see both ones, legacy IP and IPv6. Note the “peer” line for each IP in which the other IP is referenced. Nice! You have to use two different commands to show those sessions, though. (That’s what I mean when stating that FortiGate firewalls are not that sound.)
Finally, note that this setup required several other things around the mere network config which I have not shown here. That is:
a hostname for random46.weberlab.de with only at least an A record
ServerAliases on the apache2 config for the virtual host
an adjusted rewrite condition to forward HTTP -> HTTPS for this ServerAlias
running certbot again to have a valid X.509 certificate with this hostname in the subject alternative name field
Deeper Look on the Wire
I’ve captured some basic runs, that is: doing an HTTP request, getting redirected to HTTPS, as well as a ping aka echo-request. I captured on the client as well as on the server simultaneously and merged them later on. This capture is within the Ultimate PCAP already, but you can download it solely as well:
You can easily filter for
ip or
ipv6 to see only one of those Internet Protocols. Here they are side-by-side, looking at the SYN for the HTTP session:
As expected, the upper-layer protocol stuff is exactly the same after the NAT46 proxy, such as the TLS handshake with its ECDH client key exchange:
However, looking at ICMPv4 vs. ICMPv6 messages for echo-requests/-replies, the data portion looks a little different. ICMPv4 in this example used a timestamp which should be silently dropped according to RFC 7915, section 4.2. Looks like the FortiGate isn’t doing it that way but keeps the timestamp information within the data portion:
However, it’s working quite good. Nice! If you can spot any other differences between those translated protocols, please write a comment!
Fun Fact: NAT646
The other day I was on a german train using my T-Mobile tethering on my iPhone which gives perfect IPv6-native access, incl. DNS64/NAT64. Now, when surfing to this IPv4-only NAT46 domain, it eventually does a 646 translation. ;)
At SharkFest’22 EU, the Annual Wireshark User and Developer Conference, I attended a beginners’ course called “Network Troubleshooting from Scratch”, taught by the great Jasper Bongertz. In the end, we had some high-level discussions concerning various things, one of them was the insight that TCP RSTs are not only sent from a server in case the port is closed, but are also commonly sent (aka spoofed) from firewalls in case a security policy denies the connection. Key question: Can you distinguish between those spoofed vs. real TCP RSTs? Initially, I thought: no, you can’t, cause the firewalls out there do a great job.
It turned out: you can!
Closed Port vs. Denying Firewall
I did a little lab for this. In a first step, I connected to one of my servers on port 21 – old-fashioned FTP. Since there was no FTP service on the server running, every connection attempt was immediately responded by a TCP RST – just as a normal Linux server behaves. The following screenshot shows five connection attempts (FileZilla) for IPv6 and five more for legacy IP, all with a RST answer from the real server:
In a second step, I configured my Palo Alto Networks firewall to block outgoing FTP connections and to respond with a RST to the client. This is common in internal environments, where you want your clients to have some sort of immediate feedback in case of blocked/closed connections. A silent drop from the firewall would result in a client application waiting for a timeout.
This screenshot shows the TCP RST that was perfectly spoofed and sent by the firewall:
If you swap between those two screenshots, you won’t see any obvious differences, don’t you? In fact, the source IP addresses (regardless of IPv6 or legacy IP) are spoofed by the firewall as if they were the real server. Good job.
How to distinguish between them???
We just proved that the packets look exactly the same, right? This is where Jasper gave a little hint at his session:
Firewalls are always sending their spoofed RSTs with a hop limit / TTL of their own, not with the exact one from the real server.
A picture is worth a thousand words:
Let’s have a look at some pings via IPv6 and legacy IP, especially on the hop limit / TTL of the returning packets which reveal the hop count of the returning route. For this, I added a custom column to Wireshark which displays the
ipv6.hlim or ip.ttl:
That is: the returning IPv6 route is probably 10 hops away (since the remaining hop limit is 54, assuming the starting hop limit was 64), and the returning legacy IP route is probably 11 hops long.
Now let’s look at the RSTs again, focussing on the hop limit / TTL. This screenshot shows the 2x RSTs from the real server and 2x RSTs from the firewall:
Ha, I got you!
While the first two RSTs from the real server had a hop limit / TTL from 54 respectively 53, just as the real returning routes for the pings had as well, the spoofed RSTs from the firewall had values of 127 and 63, which is like some default starting values (128 or 64) minus one. It’s definitely not the hop limits the real server would have sent. Yep.
Q.E.D.
If you want to have a look at the captures by yourself, here we go: (They are in the Ultimate PCAP as well.)
Excursion: Palo Alto NGFW Policy Actions
I used a PA-220 with PAN-OS 10.2.1 for these tests. It was a little tricky to set the policies right for this. At first, blocking the application “ftp” did not work since the application detection of PAN will almost always let the first packets pass until it really detects the application. This is normal behaviour if you have other policies (further down) that are merely application based. My “FTP app deny” rule did not hit because the first SYN packet will flow through anyway, while the server is not responding (aka sending a RST), hence the PAN will log those connection attempts as “incomplete”:
That is: I used a port-based policy with TCP destination port 21 to block those connection attempts instantly. Now it was about selecting the correct type of “block” to have the firewall send TCP RSTs. The commonly used “Deny” did indeed block the connections, but did not respond with RSTs. (You will find those attempts in the pcap as well.) A “Drop“, even with an enabled “Send ICMP Unreachable” did not send back any RSTs as well, though the documentation states this. Finally, the “Reset client” did the trick. I also selected the “Send ICMP Unreachable” here, but I think it would have worked without it.
Here are the traffic logs during my tests:
allowing FTP but the server sent a TCP RST
action “deny”, that is: silently drop in this case
action “drop” with sending ICMP unreach: silently dropping as well
action “reset client” with sending ICMP unreach again. For whatever reason Palo does not highlight this policy action as red, which is a GUI bug in my point of view.
Appendix: What about UDP? –> ICMP
When it comes to UDP connections, there is no concept like a RST from the server within the same UDP session. (Remember: UDP is stateless.) Instead, the server is sending an ICMP port unreachable messages back to the client. Arrows 1 and 2 on the following screenshot. Note that the custom column in Wireshark displays two hop limits since the received ICMP packets (with their hop limits) embed the original packets that forced the error (with their own hop limits as seen by the server).
Talking about the Palo Alto Networks NGFW, it does *not* spoof the ICMP port unreachables, but sends ICMP administratively prohibited messages, clearly telling the client that there is a firewall in between. Those packets are sourced from the actual firewall IP addresses, arrows 3 and 4. Consistently, those ICMP packets have the hop limit / TTL from the egress interface, arrows 5 and 6:
BUT a BUG: Did you spot it? The Palo has an obvious bug, as it sends the ICMPv6 packets from the unspecified IPv6 of “::”. This definitely violates the standards. Nobody is perfect. ;) I opened a ticket and reported it, though I’m not expecting that they’ll fix it.
Again two more commonly used network protocols for the Ultimate PCAP: the Remote Authentication Dial-In User Service (RADIUS) and the Terminal Access Controller Access-Control System Plus (TACACS+) protocols. Captured with quite some details:
You can either download the Ultimate PCAP (recommended ;)) or merely these PCAPs:
RADIUS
Quoting Wikipedia: “Remote Authentication Dial-In User Service (RADIUS) is a networking protocol that provides centralized authentication, authorization, and accounting (AAA) management for users who connect and use a network service. […] The RADIUS server checks that the information is correct using authentication schemes such as PAP, CHAP or EAP.”
For these tests, I installed FreeRADIUS version 3.0.20 on a Ubuntu 20.04.5 LTS (5.4.0-135-generic x86_64).
At first, I used the “radtest” tool for some very basic query-responses aka request-accept messages. IPv6 and legacy IP, each time with: PAP, CHAP, and MS-CHAP:
weberjoh@vm30-test1:~$ radtest -t pap -6 bob ThisIsThePassword test2-v6.weberlab.de 10 iNJ72r0uPXP5qhAX Sent Access-Request Id 238 from [::]:51580 to [2001:470:1f0b:16b0:20c:29ff:fea8:26f7]:1812 length 101
User-Name = "bob"
User-Password = "ThisIsThePassword"
NAS-IPv6-Address = ::1
NAS-Port = 10
Message-Authenticator = 0x00
Cleartext-Password = "ThisIsThePassword"
Received Access-Accept Id 238 from [2001:470:1f0b:16b0:20c:29ff:fea8:26f7]:1812 to [::]:0 length 32
Reply-Message = "Hello, bob"
weberjoh@vm30-test1:~$ radtest -t chap -6 bob ThisIsThePassword test2-v6.weberlab.de 10 iNJ72r0uPXP5qhAX
Sent Access-Request Id 23 from [::]:46192 to [2001:470:1f0b:16b0:20c:29ff:fea8:26f7]:1812 length 86
User-Name = "bob"
CHAP-Password = 0xea8d36b4906c71784c75e17983e36cab66
NAS-IPv6-Address = ::1
NAS-Port = 10
Message-Authenticator = 0x00
Cleartext-Password = "ThisIsThePassword"
Received Access-Accept Id 23 from [2001:470:1f0b:16b0:20c:29ff:fea8:26f7]:1812 to [::]:0 length 32
Reply-Message = "Hello, bob"
weberjoh@vm30-test1:~$ radtest -t mschap -6 bob ThisIsThePassword test2-v6.weberlab.de 10 iNJ72r0uPXP5qhAX
Sent Access-Request Id 22 from [::]:60664 to [2001:470:1f0b:16b0:20c:29ff:fea8:26f7]:1812 length 141
User-Name = "bob"
MS-CHAP-Password = "ThisIsThePassword"
NAS-IPv6-Address = ::1
NAS-Port = 10
Message-Authenticator = 0x00
Cleartext-Password = "ThisIsThePassword"
MS-CHAP-Challenge = 0x9cfe6e183debe56d
MS-CHAP-Response = 0x0001000000000000000000000000000000000000000000000000517e32e81fc99c2d05fc072ce33afe6eb5a01a782532c359
Received Access-Accept Id 22 from [2001:470:1f0b:16b0:20c:29ff:fea8:26f7]:1812 to [::]:0 length 96
Reply-Message = "Hello, bob"
MS-CHAP-MPPE-Keys = 0x00000000000000001c2e158974b065d412b4456d6ebf7574
MS-MPPE-Encryption-Policy = Encryption-Allowed
MS-MPPE-Encryption-Types = RC4-40or128-bit-Allowed
weberjoh@vm30-test1:~$
weberjoh@vm30-test1:~$
weberjoh@vm30-test1:~$ radtest -t pap bob ThisIsThePassword test2-v4.weberlab.de 10 iNJ72r0uPXP5qhAX Sent Access-Request Id 19 from 0.0.0.0:35337 to 194.247.5.27:1812 length 89
User-Name = "bob"
User-Password = "ThisIsThePassword"
NAS-IP-Address = 127.0.0.1
NAS-Port = 10
Message-Authenticator = 0x00
Cleartext-Password = "ThisIsThePassword"
Received Access-Accept Id 19 from 194.247.5.27:1812 to 0.0.0.0:0 length 32
Reply-Message = "Hello, bob"
weberjoh@vm30-test1:~$ radtest -t chap bob ThisIsThePassword test2-v4.weberlab.de 10 iNJ72r0uPXP5qhAX
Sent Access-Request Id 52 from 0.0.0.0:41381 to 194.247.5.27:1812 length 74
User-Name = "bob"
CHAP-Password = 0xe58f51cf7e8b048d3d8ebbf5837378e277
NAS-IP-Address = 127.0.0.1
NAS-Port = 10
Message-Authenticator = 0x00
Cleartext-Password = "ThisIsThePassword"
Received Access-Accept Id 52 from 194.247.5.27:1812 to 0.0.0.0:0 length 32
Reply-Message = "Hello, bob"
weberjoh@vm30-test1:~$ radtest -t mschap bob ThisIsThePassword test2-v4.weberlab.de 10 iNJ72r0uPXP5qhAX
Sent Access-Request Id 102 from 0.0.0.0:43642 to 194.247.5.27:1812 length 129
User-Name = "bob"
MS-CHAP-Password = "ThisIsThePassword"
NAS-IP-Address = 127.0.0.1
NAS-Port = 10
Message-Authenticator = 0x00
Cleartext-Password = "ThisIsThePassword"
MS-CHAP-Challenge = 0x336bbd41fe6c4c2d
MS-CHAP-Response = 0x00010000000000000000000000000000000000000000000000004ec1a471e0992133be0bed6a714beffd62802495e0e34a5f
Received Access-Accept Id 102 from 194.247.5.27:1812 to 0.0.0.0:0 length 96
Reply-Message = "Hello, bob"
MS-CHAP-MPPE-Keys = 0x00000000000000001c2e158974b065d412b4456d6ebf7574
MS-MPPE-Encryption-Policy = Encryption-Allowed
MS-MPPE-Encryption-Types = RC4-40or128-bit-Allowed
Secondly, I did some “Test User Credentials” on a Fortinet FortiWiFi FWF-61E with FortiOS 7.0.9 within the RADIUS Servers profile. I did the following methods in that order: PAP, CHAP, MS-CHAP, and MS-CHAP-v2. The FortiGate is not capable of any secure authentication schemes nor communicating via IPv6. (Why is this called a next-gen firewall?)
Thirdly I did some authentication tests on a Palo Alto Networks PA-220 with PAN-OS 10.2.3. I wanted to test some advanced authentication variants of RADIUS that are secured by TLS. Therefore, I ran the “/etc/freeradius/3.0/certs/bootstrap” script on the FreeRADIUS server to get some certificates in place, edited some config files (I don’t remember which one exactly, but in the end, it worked – hahaha), exported the snakeoil root CA, imported it into the Palo Alto NGFW, marked it as “Trusted Root CA”, created an appropriate Certificate Profile, and selected this profile within the RADIUS server profile. (This would be an own blog post just about using secure RADIUS with the PAN. ;)) In the end, I was able to test the following auth protocols: PEAP-MSCHAPv2, PEAP with GTC, and EAP-TTLS with PAP. I did this by selecting the respective method, followed by the useful “test authentication […]” CLI commands. No commit needed to test all those stuff, though freshly configured within the GUI. Great.
This was the output during the tests on the PAN CLI:
weberjoh@pa> test authentication authentication-profile test2 username bob password
Enter password :
Target vsys is not specified, user "bob" is assumed to be configured with a shared auth profile.
Do allow list check before sending out authentication request...
name "bob" is in group "all"
Egress: No service source route is set, might use destination source route if configured
Test authentication to RADIUS server 2001:470:1f0b:16b0:20c:29ff:fea8:26f7:1812 for user: "bob" (with anonymous outer id) using protocol: PEAP with MSCHAPv2
Successful EAPOL auth.
Authentication succeeded against RADIUS server at 2001:470:1f0b:16b0:20c:29ff:fea8:26f7:1812 for user "bob"
Authentication succeeded for user "bob"
weberjoh@pa>
weberjoh@pa>
weberjoh@pa> test authentication authentication-profile test2 username bob password
Enter password :
Target vsys is not specified, user "bob" is assumed to be configured with a shared auth profile.
Do allow list check before sending out authentication request...
name "bob" is in group "all"
Egress: No service source route is set, might use destination source route if configured
Test authentication to RADIUS server 2001:470:1f0b:16b0:20c:29ff:fea8:26f7:1812 for user: "bob" (with anonymous outer id) using protocol: PEAP with GTC
Successful EAPOL auth.
Authentication succeeded against RADIUS server at 2001:470:1f0b:16b0:20c:29ff:fea8:26f7:1812 for user "bob"
Authentication succeeded for user "bob"
weberjoh@pa>
weberjoh@pa>
weberjoh@pa> test authentication authentication-profile test2 username bob password
Enter password :
Target vsys is not specified, user "bob" is assumed to be configured with a shared auth profile.
Do allow list check before sending out authentication request...
name "bob" is in group "all"
Egress: No service source route is set, might use destination source route if configured
Test authentication to RADIUS server 2001:470:1f0b:16b0:20c:29ff:fea8:26f7:1812 for user: "bob" (with anonymous outer id) using protocol: EAP-TTLS with PAP
Successful EAPOL auth.
Authentication succeeded against RADIUS server at 2001:470:1f0b:16b0:20c:29ff:fea8:26f7:1812 for user "bob"
Authentication succeeded for user "bob"
weberjoh@pa>
And since I ran the FreeRADIUS server in debug mode, I’ll hand out those debug logs as well, just in case you’re interested. 3320 lines for those 3x auth tests. Wow. ;) Click here to download it.
Wiresharking
For all these tests I used the same RADIUS shared secret of
iNJ72r0uPXP5qhAX. Paste it into the Edit -> Preferences -> Protocols -> RADIUS section to have Wireshark decrypt some stuff:
And now, some Wireshark screenshots, while I strongly encourage you to download the Ultimate PCAP and click around it by yourself. Use the display filter of
radius.
I’ve only used some basic AVPs here since I did not use RADIUS in production with several different vendors and stuff. However, you get the idea. And there are already enough fields to dig into. ;) Furthermore, I only used RADIUS with UDP (not sure whether TCP is used at all for RADIUS?) and only for authentication on port 1812, not accounting on port 1813. I also missed mistyping the user password to have a reject. Yeah, that’s the way it is.
TACACS+
To simply state the TACACS article on Wikipedia again: “TACACS+ is a Cisco designed extension to TACACS that encrypts the full content of each packet. Moreover, it provides granular control in the form of command-by-command authorization. […] TACACS+ encrypts all the information mentioned above and therefore does not have the vulnerabilities present in the RADIUS protocol.”
TACACS+ uses TCP as transport and has its well-known port of 49. For my lab, I used an Aruba ClearPass Policy Manager version 6.9.10.134806 as the server and a Cisco ASR1001-X with IOS XE Version 17.03.04a as the client aka NAS. (I apologise for being IPv4-only this time…)
Fortunately, Wireshark is able to decrypt all TACACS+ messages in case the shared secret is provided, which is true for my lab:
John3.16. Edit -> Preferences -> Protocols -> TACACS+:
As always, if you want to see the whole TCP sessions aka streams (incl. the three-way handshakes), you have to use a display filter like
tcp.port eq 49. The display filter for only the payload of TACACS+ (with the plus) is
tacplus. (For the predecessor, which is TACACS without the plus, it is
tacacs. But this is not used here.) I did the following steps during the capturing:
2x login with a wrong password -> authentication failed
correct login -> authentication passed
some CLI commands on the router to have a –> authorization